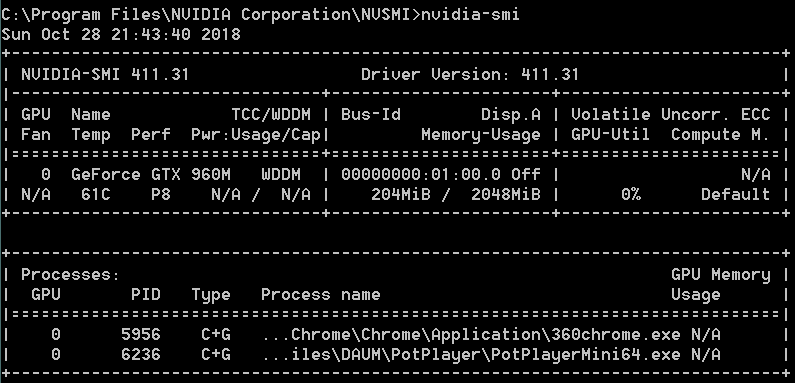
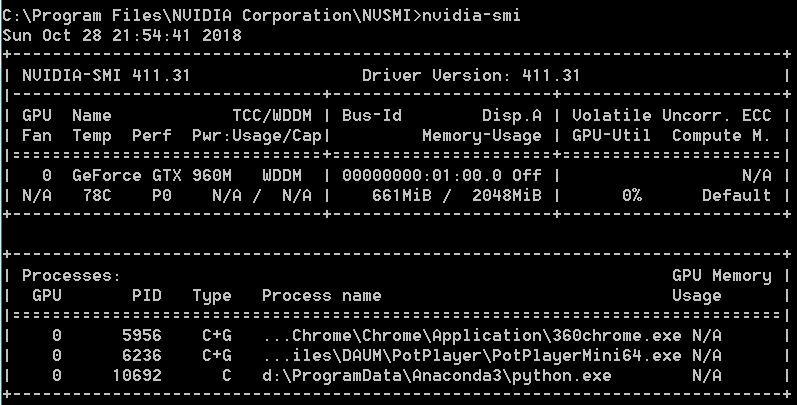
使用 jupyter,python3.6,TensorFlow-gpu-1.11,CUDA10.0,cuDNN7.3.1.20,Windows7-x64 本地硬件:笔记本,8×i7-4700,GTX960M(2GB),内存 8GB
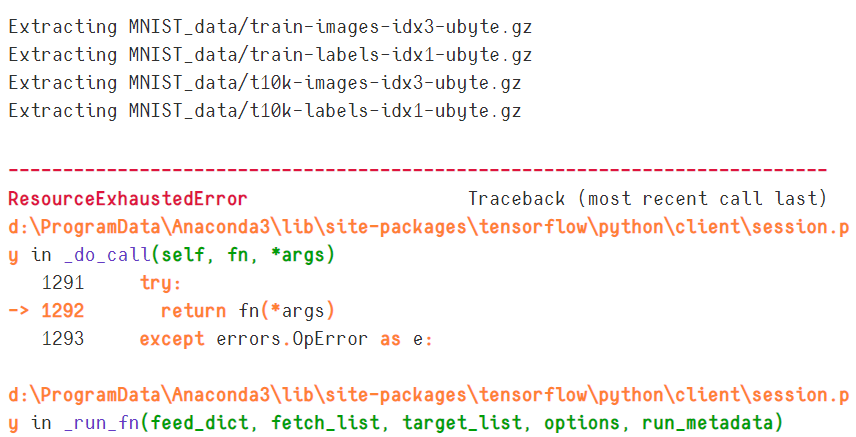
本地无论使用 GPU 或者强制使用 CPU 都会出现资源耗尽错误,
用阿里云天池实验室的 notebook 半小时可以跑完,
我想是不是要换显卡了?请各位大神指正一下
用 CNN 实现一个简单的内置数据集 MNIST 分类任务,代码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets ('MNIST_data/',one_hot= True)
# 每个批次的大小:
batch_size = 128
# 计算一共有多少批次
n_batch = mnist.train.num_examples//batch_size
# 初始化权重值 W:
def weight_variable (shape):
initial = tf.truncated_normal (shape=shape,stddev=0.1)
return tf.Variable (initial)
# 初始化偏置值 b
def biases_variable (shape):
initial = tf.constant (0.1,shape=shape)
return tf.Variable (initial)
# 卷积层
def conv2d (x,W):
''' x-input tensor of shape [batch,in_height,in_weight,in_channels]
W-filter/kernel tensor of shape [filter_height,filter_weight,
in_channels,out_channels]
stride [0]=stride [3]=1,
stride [1]-x 步长
stride [2]-y 步长
padding-SAME 如果不够则补零 (卷积后图像大小与输入一致),VALID-不补(多余的舍弃)
'''
return tf.nn.conv2d (x,W,strides=[1,1,1,1],padding='SAME')
# 池化层
def max_pool_2x2 (x):
'''ksize [1,x,y,1],x,y 表示窗口大小'''
return tf.nn.max_pool (x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# 定义 2 个 placeholder
x = tf.placeholder (tf.float32,[None,784]) #28x28
y = tf.placeholder (tf.float32,[None,10])
# 将 x 转换为向量
'''[batch,in_height,in_weight,in_channels]'''
x_image = tf.reshape (x,[-1,28,28,1])
# 初始化第一个卷积层的 W,b
'''窗口 x,窗口 y,channels,卷积核 filter 个数(特征图数量)'''
W_conv1 = weight_variable ([5,5,1,32])
'''每一个卷积核对应一个偏置值'''
b_conv1 = biases_variable ([32])
# 第一层的卷积与池化
'''28%2=0,所以 SAME 不补,padding=0,池化后的 x 应该是,
((28+2×0-2)/2 )+1=14
第 1 个 2 是 2 倍的 padding,第 2 个 2 是窗口 x=2,第三个 2 是 stride
池化输入与窗口都是正方形,所以池化后的 y=14 ,
池化后图片 14×14
'''
h_conv1 = tf.nn.relu (conv2d (x_image,W_conv1)+b_conv1)
h_pool1 = max_pool_2x2 (h_conv1) #14×14,32 张
# 初始化第二个卷积层的 W,b
'''窗口 x,窗口 y,channels(上一层特征图数量),卷积核 filter 个数(特征图数量)'''
W_conv2 = weight_variable ([5,5,32,64])
'''每一个卷积核对应一个偏置值'''
b_conv2 = biases_variable ([64])
# 第二层的卷积与池化
'''((14+2×0-2)/2 )+1=7,7×7'''
h_conv2 = tf.nn.relu (conv2d (h_pool1,W_conv2)+b_conv2)
h_pool2 = max_pool_2x2 (h_conv2)#7×7,64 张
# 初始化第一个全连接层
W_fc1 = weight_variable ([7*7*64,1024])
b_fc1 = biases_variable ([1024])
# 求第一个全连接层的输出
#1,将最后一层卷积池化层的输出变为扁平化
h_pool2_flat = tf.reshape (h_pool2,[-1,7*7*64])
#2,计算全连接层的输出
h_fc1 = tf.nn.relu (tf.matmul (h_pool2_flat,W_fc1)+b_fc1) #-1×1024
#keep_prob 用来表示全连接层的输出率
keep_prob = tf.placeholder (tf.float32)
h_fc1_drop = tf.nn.dropout (h_fc1,keep_prob)
# 初始化第二个全连接层
W_fc2 = weight_variable ([1024,10])
b_fc2 = biases_variable ([10])
# 计算输出
'''
-1 是 batch,这里的 batch 是 100,
所以这里输出的是 100×10,
也就是每行是 1 张图片,一共有 100 行
每一列是 1 个特征,一共有 10 列
'''
prediction = tf.nn.softmax (tf.matmul (h_fc1,W_fc2)+b_fc2) #-1×10
# 交叉熵损失函数
coss_entropy = tf.reduce_mean (tf.nn.softmax_cross_entropy_with_logits_v2 (labels=y,logits= prediction))
# 使用 Adam 优化器
train_step = tf.train.AdamOptimizer (1e-4).minimize (coss_entropy)
# 结果存放在一个布尔列表中
correct_prediction = tf.equal (tf.argmax (prediction,1),tf.argmax (y,1))
# 求准确率
accuracy = tf.reduce_mean (tf.cast (correct_prediction,tf.float32))
with tf.Session () as sess:
sess.run (tf.global_variables_initializer ())
for epoch in range (21):
for batch in range (n_batch):
batch_xs,batch_ys = mnist.train.next_batch (batch_size)
sess.run (train_step,feed_dict = {x:batch_xs,
y:batch_ys,
keep_prob:0.7})
acc = sess.run (accuracy,feed_dict = {x:mnist.test.images,
y:mnist.test.labels,
keep_prob:1.0})
print ("第"+str (epoch)+"次迭代,测试集准确率是"+str (acc))
ResourceExhaustedError Traceback (most recent call last) d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py in _do_call (self, fn, *args) 1291 try:-> 1292return fn (*args) 1293 except errors.OpError as e:d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py in _run_fn (feed_dict, fetch_list, target_list, options, run_metadata) 1276 return self._call_tf_sessionrun (-> 1277 options, feed_dict, fetch_list, target_list, run_metadata) 1278 d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py in _call_tf_sessionrun (self, options, feed_dict, fetch_list, target_list, run_metadata) 1366 self._session, options, feed_dict, fetch_list, target_list,-> 1367 run_metadata) 1368 ResourceExhaustedError: OOM when allocating tensor with shape [10000,32,28,28] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[{{node Conv2D}} = Conv2D [T=DT_FLOAT, data_format=“NCHW”, dilations=[1, 1, 1, 1], padding=“SAME”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](Conv2D-0-TransposeNHWCToNCHW-LayoutOptimizer, Variable/read)]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. [[{{node Mean_1/_11}} = _Recv client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name=“edge_72_Mean_1”, tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.During handling of the above exception, another exception occurred:ResourceExhaustedError Traceback (most recent call last) in () 127 acc = sess.run (accuracy,feed_dict = {x:mnist.test.images, 128 y:mnist.test.labels,–> 129 keep_prob:1.0}) 130 131 print (“第”+str (epoch)+“次迭代,测试集准确率是”+str (acc)) d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py in run (self, fetches, feed_dict, options, run_metadata) 885 try: 886 result = self._run (None, fetches, feed_dict, options_ptr,–> 887 run_metadata_ptr) 888 if run_metadata: 889 proto_data = tf_session.TF_GetBuffer (run_metadata_ptr) d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py in _run (self, handle, fetches, feed_dict, options, run_metadata) 1108 if final_fetches or final_targets or (handle and feed_dict_tensor): 1109 results = self._do_run (handle, final_targets, final_fetches,-> 1110 feed_dict_tensor, options, run_metadata) 1111 else: 1112 results = [] d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py in _do_run (self, handle, target_list, fetch_list, feed_dict, options, run_metadata) 1284 if handle is None: 1285 return self._do_call (_run_fn, feeds, fetches, targets, options,-> 1286 run_metadata) 1287 else: 1288 return self._do_call (_prun_fn, handle, feeds, fetches) d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py in _do_call (self, fn, *args) 1306 self._config.experimental.client_handles_error_formatting): 1307 message = error_interpolation.interpolate (message, self._graph)-> 1308raise type (e)(node_def, op, message) 1309 1310 def _extend_graph (self):ResourceExhaustedError: OOM when allocating tensor with shape [10000,32,28,28] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[{{node Conv2D}} = Conv2D [T=DT_FLOAT, data_format=“NCHW”, dilations=[1, 1, 1, 1], padding=“SAME”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](Conv2D-0-TransposeNHWCToNCHW-LayoutOptimizer, Variable/read)]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. [[{{node Mean_1/_11}} = _Recv client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name=“edge_72_Mean_1”, tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.Caused by op ‘Conv2D’, defined at: File “d:\ProgramData\Anaconda3\lib\runpy.py”, line 193, in _run_module_as_main “main”, mod_spec) File “d:\ProgramData\Anaconda3\lib\runpy.py”, line 85, in _run_code exec (code, run_globals) File “d:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py”, line 16, in app.launch_new_instance () File “d:\ProgramData\Anaconda3\lib\site-packages\traitlets\config\application.py”, line 658, in launch_instance app.start () File “d:\ProgramData\Anaconda3\lib\site-packages\ipykernel\kernelapp.py”, line 486, in start self.io_loop.start () File “d:\ProgramData\Anaconda3\lib\site-packages\tornado\platform\asyncio.py”, line 127, in start self.asyncio_loop.run_forever () File “d:\ProgramData\Anaconda3\lib\asyncio\base_events.py”, line 422, in run_forever self._run_once () File “d:\ProgramData\Anaconda3\lib\asyncio\base_events.py”, line 1432, in _run_once handle._run () File “d:\ProgramData\Anaconda3\lib\asyncio\events.py”, line 145, in _run self._callback (*self._args) File “d:\ProgramData\Anaconda3\lib\site-packages\tornado\platform\asyncio.py”, line 117, in _handle_events handler_func (fileobj, events) File “d:\ProgramData\Anaconda3\lib\site-packages\tornado\stack_context.py”, line 276, in null_wrapper return fn (*args, **kwargs) File “d:\ProgramData\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py”, line 450, in _handle_events self._handle_recv () File “d:\ProgramData\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py”, line 480, in _handle_recv self._run_callback (callback, msg) File “d:\ProgramData\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py”, line 432, in _run_callback callback (*args, **kwargs) File “d:\ProgramData\Anaconda3\lib\site-packages\tornado\stack_context.py”, line 276, in null_wrapper return fn (*args, **kwargs) File “d:\ProgramData\Anaconda3\lib\site-packages\ipykernel\kernelbase.py”, line 283, in dispatcher return self.dispatch_shell (stream, msg) File “d:\ProgramData\Anaconda3\lib\site-packages\ipykernel\kernelbase.py”, line 233, in dispatch_shell handler (stream, idents, msg) File “d:\ProgramData\Anaconda3\lib\site-packages\ipykernel\kernelbase.py”, line 399, in execute_request user_expressions, allow_stdin) File “d:\ProgramData\Anaconda3\lib\site-packages\ipykernel\ipkernel.py”, line 208, in do_execute res = shell.run_cell (code, store_history=store_history, silent=silent) File “d:\ProgramData\Anaconda3\lib\site-packages\ipykernel\zmqshell.py”, line 537, in run_cell return super (ZMQInteractiveShell, self).run_cell (*args, **kwargs) File “d:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py”, line 2662, in run_cell raw_cell, store_history, silent, shell_futures) File “d:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py”, line 2785, in _run_cell interactivity=interactivity, compiler=compiler, result=result) File “d:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py”, line 2903, in run_ast_nodes if self.run_code (code, result): File “d:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py”, line 2963, in run_code exec (code_obj, self.user_global_ns, self.user_ns) File “”, line 59, in h_conv1 = tf.nn.relu (conv2d (x_image,W_conv1)+b_conv1) File “”, line 29, in conv2d return tf.nn.conv2d (x,W,strides=[1,1,1,1],padding=‘SAME’) File “d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\ops\gen_nn_ops.py”, line 957, in conv2d data_format=data_format, dilations=dilations, name=name) File “d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\framework\op_def_library.py”, line 787, in _apply_op_helper op_def=op_def) File “d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\util\deprecation.py”, line 488, in new_func return func (*args, **kwargs) File “d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py”, line 3272, in create_op op_def=op_def) File “d:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py”, line 1768, in init self._traceback = tf_stack.extract_stack () ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape [10000,32,28,28] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[{{node Conv2D}} = Conv2D [T=DT_FLOAT, data_format=“NCHW”, dilations=[1, 1, 1, 1], padding=“SAME”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](Conv2D-0-TransposeNHWCToNCHW-LayoutOptimizer, Variable/read)]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. [[{{node Mean_1/_11}} = _Recv client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name=“edge_72_Mean_1”, tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
烤腰子 2018-10-25 17:37:17