文 / Toby Boyd、Yanan Cao、Sanjoy Das、Thomas Joerg、Justin Lebar
XLA 是 TensorFlow 图表的编译器,只需更改极少的源代码,便可加速您的 TensorFlow ML 模型。这篇文章将介绍 XLA,并说明如何在您自己的代码中试用 XLA。
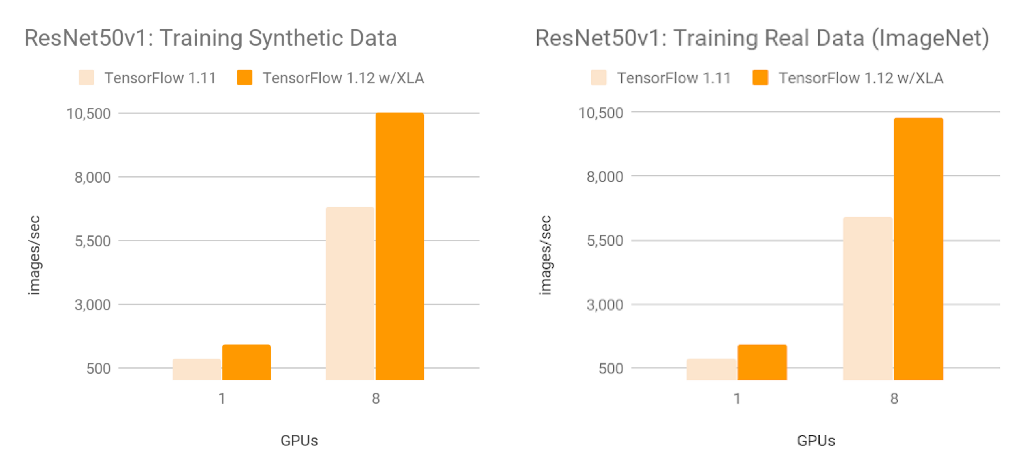
在使用 NVIDIA® Tesla® V100 GPU 训练 ResNet50 v1.0 时,相比 TF 1.11(未配备 XLA),TensorFlow 1.12(配备 XLA)的性能有显著提升:合成数据为每秒 10526 张图像,真实数据为每秒 10267 张图像(复制说明请见附录)。我们在各种内部模型上观察到速度提升(从 1.13 倍至 3.04 倍)。
XLA:成功编译 TensorFlow!
通常情况下,当您运行 TensorFlow 图表时,所有运算都由 TensorFlow 图表执行器单独执行。每个运算都会安装由图表执行器分派的预编译 GPU 内核(随附于 TensorFlow 二进制文件中)。
XLA 提供了另一种运行 TF 模型的模式:这种模式会将您的 TensorFlow 图表编译成专为您的模型生成的 GPU 内核序列。由于这些是您程序独有的内核,因此它们可以利用模型的特定信息进行优化。
举一个例子,我们一起看看 XLA 在简单 TensorFlow 计算环境中的优化过程:
1 def model_fn(x,y,z):
2 return tf.reduce_sum(x + y * z)
如果运行模型时不使用 XLA,图表会启动三个内核,分别用于乘法、加法和减法。
但是,XLA 可以优化图表,以便在启动单个内核时计算结果。方法是将加法、乘法和减法 “融合” 到单个 GPU 内核中。此外,这种融合运算不会将 yz 和 x+yz 生成的中间值写入内存,而是将这些中间计算的结果直接 “流式传输” 给用户,并完整保存在 GPU 寄存器中。
融合是 XLA 最重要的一种优化方式。内存带宽通常是硬件加速器上最稀缺的资源,因此删除内存运算是提升性能的最佳方法之一。
在模型中使用 XLA
XLA 使用 xla.compile API,让您可以在部分 TensorFlow 图表上显式调用 XLA 编译器。xla.compile 会接受生成 TensorFlow 计算的 Python 函数,然后连接所生成的计算以供 XLA 编译。xla.compile 还会返回张量列表,其中每个张量对应传入函数构建的计算结果,但现在会立即由 XLA 优化。
因此,通过调用 xla.compile,您可以使用 XLA 运行以上由 model_fn 生成的计算,如下所示:
1 from tensorflow.contrib.compiler import xla
2
3 def model_fn (x, y, z):
4 return tf.reduce_sum (x + y * z)
5
6 def create_and_run_graph ():
7 with tf.Session () as sess:
8 x = tf.placeholder (tf.float32, name=‘x’)
9 y = tf.placeholder (tf.float32, name=‘y’)
10 z = tf.placeholder (tf.float32, name=‘z’)
11 result = xla.compile (computation=model_fn, inputs=(x, y, z))[0]
12 # result is a normal Tensor (albeit one that is computed by an XLA
13 # compiled executable) and can be used like any other Tensor.
14 result = tf.add (result, result)
15 return sess.run (result, feed_dict={ … })
您可以使用命令行标记(或其他任意逻辑)来控制是否由 XLA 编译计算。模型通常按照以下方式调用 xla.compile 以便完成简单实验。
1 if should_use_xla ():
2 result = xla.compile (model_fn, (x, y, z))[0]
3 else:
4 result = model_fn (x, y, z)
我们已经设置 colab,让您可以在稍微复杂一些的模型上使用 xla.compile。
xla.compile 不是在 TensorFlow 子图表上调用 XLA 的唯一方法;具体来说,有一些方法可以让 TensorFlow 自动 找到与 XLA 兼容的子图表并使用 XLA 进行编译,但我们不会在这篇文章中讨论这些方法。
使用 XLA 的注意事项
第一,XLA GPU 后端目前仍处于实验阶段,虽然我们没有发现任何重大问题,但其尚未进行广泛的生产使用测试。
第二,xla.compile 仍不适用于 model.fit 等 Keras 高级 API(但您可以使用 Keras 运算),也不支持 Eager 模式。我们正在积极开发 API 以便在这些模式下启用 XLA;敬请期待。
第三,XLA 无法编译所有 TensorFlow 图表;只有具有以下属性的图表才能传递给 xla.compile。
所有运算都必须具有可推断的形状
XLA 需要能够在给定计算输入的情况下,推断出其编译的所有运算的形状。因此,如果模型函数生成的 Tensor 具有不可推断的形状,则运行时将会出现错误,进而导致运行失败。(在这个例子中,tf.expand_dims 的输出形状取决于 random_dim_size,但其无法在给定 x、y 和 z 的情况下推断出来。)
请注意,由于 XLA 是 JIT 编译器,形状会因不同的运行过程而异,前提是能够根据给定的集群输入条件推断出来。这个例子很好地体现了这一点。
XLA 必须支持所有运算
并非所有 TensorFlow 运算都可由 XLA 编译,如果模型中有 XLA 不支持的运算,XLA 编译就会失败。例如,XLA 不支持 tf.where 运算,因此如果您的模型函数包含此运算,使用 xla.compile 运行模型时便会失败。
XLA 支持的每项 TensorFlow 运算都可在 tensorflow/compiler/tf2xla/kernels/ 中调用 REGISTER_XLA_OP,因此您可以使用 grep 来搜索 REGISTER_XLA_OP 宏实例,以查找支持的 TensorFlow 运算列表。
附录
在 Google 基准下的表现
下方是所有 XLA 团队基准模型(在 V100 GPU 上运行)的 TensorFlow 在使用和不使用 XLA 时的相对加速 / 减速图。我们没有任何保留;这是我们今天在评估编译器时使用的全部基准。
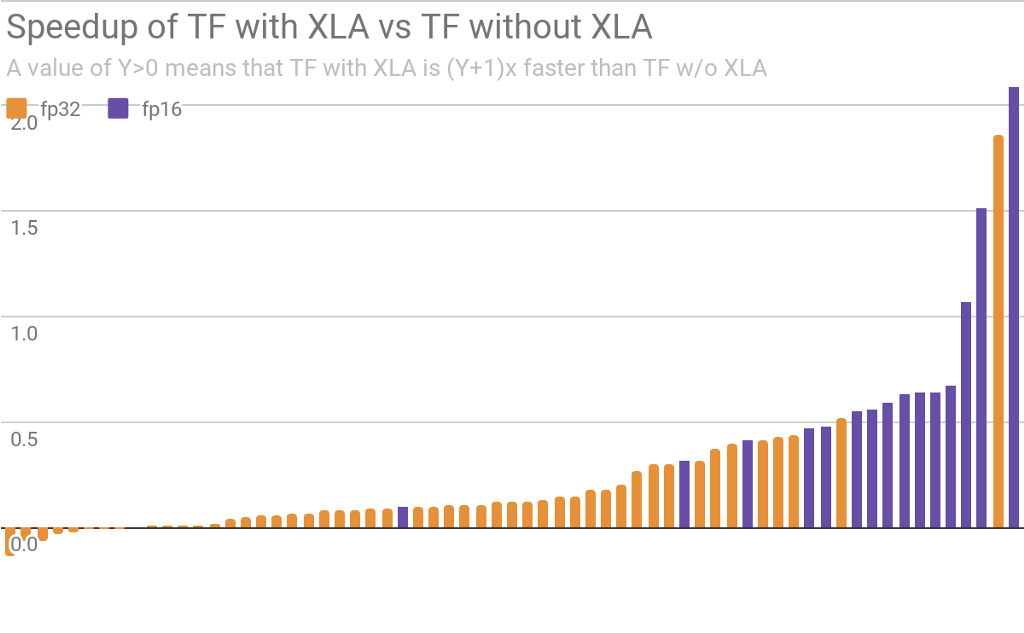
图中每个竖条代表一个完整的模型,例如 “resnet50 训练图像 / 秒” 或 “基于 Google 内部模型的推理吞吐量”。X 轴按加速情况排序。
您的情况可能有所不同,特别是我们已经根据其中很多基准专门对 XLA 进行了优化!但是,其中很多基准可以立即使用,而且效果非常出色,我们还将持续作出改进。
复制 ResNet50 v1.0 基准
以下部分将介绍如何设置 Google Cloud 实例和执行 ResNet50 基准。
准备数据
只有进行真实数据测试时需要完成这个步骤,并可能需时几小时。我们建议只在 CPU 实例中执行此步骤,以降低计算成本。根据 imagenet_to_gcs.py 说明创建 TFRecord 格式的 imagenet 数据,并将其发送至 Google Cloud Storage 存储分区。
创建 GCE 实例
下方代码片段会在使用八个 Tesla® V100 GPU 的 Google Cloud Platform 上创建 Google 深度学习 VM。
1 export INSTANCE_NAME=“xla-benchmark-8xV100”
2 export IMAGE_FAMILY=“tf-1-12-cu100”
3 export PROJECT_NAME=“”
4
5 gcloud beta compute instances create $INSTANCE_NAME \
6 --project=$PROJECT_NAME \
7 --machine-type=n1-standard-64 \
8 --maintenance-policy=TERMINATE \
9 --accelerator=type=nvidia-tesla-v100,count=8 \
10 --tags=http-server,https-server \
11 --image-family=$IMAGE_FAMILY \
12 --image-project=deeplearning-platform-release \
13 --boot-disk-size=100GB \
14 --boot-disk-type=pd-ssd \
15 --local-ssd interface=nvme \
16 --local-ssd interface=nvme \
17 --local-ssd interface=nvme \
18 --local-ssd interface=nvme \
19 --metadata install-nvidia-driver=True
20
21 ## Combines the 4 local nvme SSD drives into a single RAID 0 drive.
22 # Install raid management tool.
23 sudo apt-get update && sudo apt-get install mdadm --no-install-recommends
24
25 # Creates RAID 0 array.
26 sudo mdadm --create /dev/md0 --level=0 --raid-devices=4
27 /dev/nvme0n1 /dev/nvme0n2 /dev/nvme0n3 /dev/nvme0n4
28
29 # Formats and mounts the array.
30 sudo mkfs.ext4 -F /dev/md0
31 sudo mkdir -p /data/imagenet
32 sudo mount /dev/md0 /data
33 sudo chmod a+w /data
34
35 # Installs custom TensorFlow 1.12 binary with AVX2. Binary included on
36 # the image already has XLA but the custom binary is compiled with AVX2.
37 sudo pip install --force-reinstall https://storage.googleapis.com/t … mu-linux_x86_64.whl
执行基准测试
1 gcloud compute SSH $INSTANCE_NAME
2
3 # Clone TensorFlow benchmark repository.
4 git clone GitHub - tensorflow/benchmarks: A benchmark framework for Tensorflow && cd benchmarks
5 git reset --hard 1e7d788042dfc6d5e5cd87410c57d5eccee5c664
6 cd scripts/tf_cnn_benchmarks
7
8 ## Synthetic data test
9
10 # 8 GPUs
11 python tf_cnn_benchmarks.py \
12 --batch_size=364 \
13 --num_batches=100 \
14 --model=resnet50 \
15 --optimizer=momentum \
16 --variable_update=replicated \
17 --all_reduce_spec=nccl \
18 --use_fp16=True \
19 --nodistortions \
20 --gradient_repacking=2 \
21 --compute_lr_on_cpu=True \
22 --single_l2_loss_op=True \
23 --xla_compile=True \
24 --num_gpus=8 \
25 --loss_type_to_report=base_loss
26
27 # 1 GPU
28 python tf_cnn_benchmarks.py \
29 --batch_size=364 \
30 --num_batches=100 \
31 --model=resnet50 \
32 --optimizer=momentum \
33 --use_fp16=True \
34 --nodistortions \
35 --compute_lr_on_cpu=True \
36 --single_l2_loss_op=True \
37 --xla_compile=True \
38 --loss_type_to_report=base_loss
39
40 ## Real data test
41 # add --data_dir=/data/imagenet to the 1 or 8 GPU command.
大白白 2018-11-22 15:22:03