在使用 tf 搭建 lstm 时,无论训练还是测试时,都必须保持 batch_size 不变,否则会报错,但搭建纯 CNN 时并不会出现这种情况,有什么解决方案吗?
小筑 123 2018-5-22 16:52:42
在使用 tf 搭建 lstm 时,无论训练还是测试时,都必须保持 batch_size 不变,否则会报错,但搭建纯 CNN 时并不会出现这种情况,有什么解决方案吗?
小筑 123 2018-5-22 16:52:42
yunhai_luo:
楼主能澄清一下怎么 “必须保持 batch_size 不变” 吗?是指训练和测试各自的 batch_size 在各自的运行中不变?还是指测试的 batch_size 等于训练的 batch_size?会报什么错?
2018-5-23 14:50
小筑 123: 回复 yunhai_luo :
在训练和测试的时候,都必须保持相同的且固定不变的 batch_size,比如测试的时候,由于验证的数据比较少,我可能会将所有数据一次性输入 feed_dict,那此时喂得数据的 batch_size 就变了,会报错
2018-5-26 17:38
小筑 123: 回复 yunhai_luo :
报错信息参见下一楼回复,谢谢
2018-5-26 17:48
2018-5-23 14:50
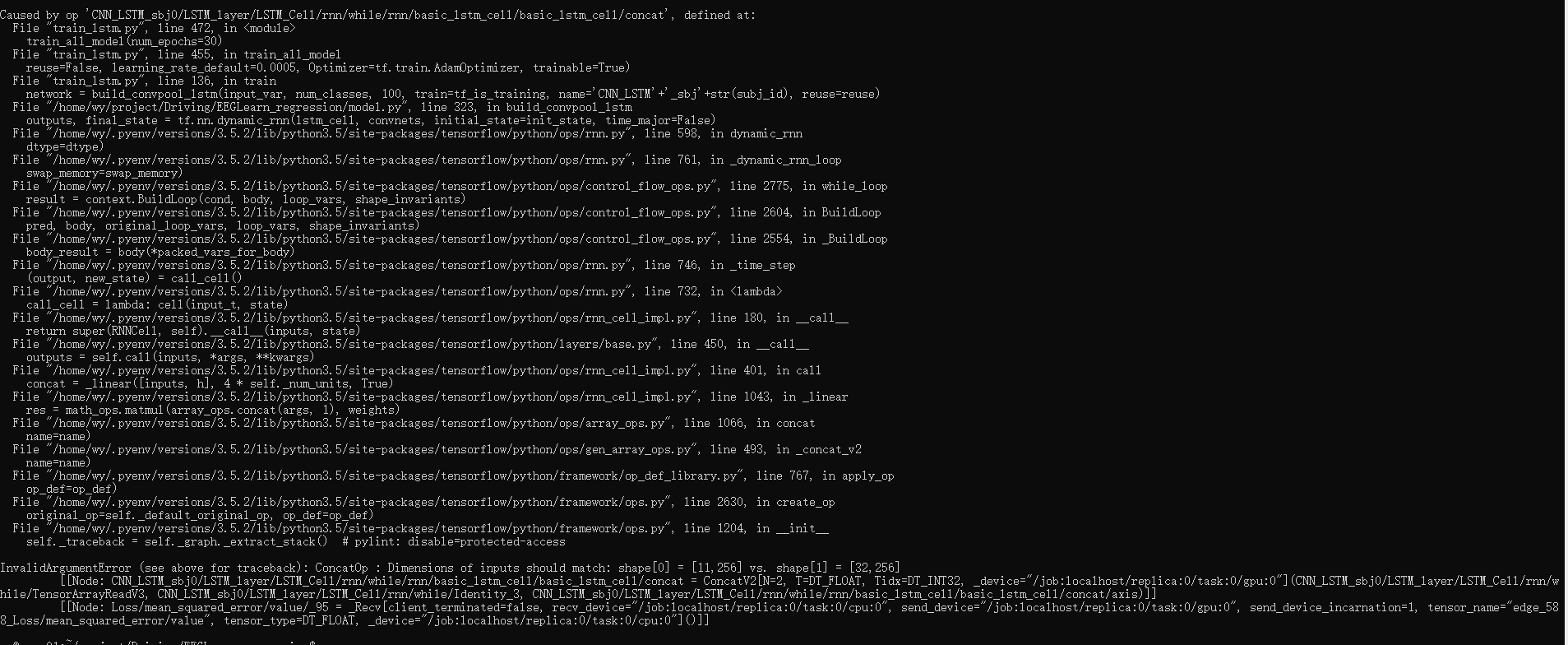
图片中的 batch_size 为 32,然后我喂了 11 个数据进去
C:\Users\YangW\Desktop\lstm_batch.png
而且我发现在定义模型的时候,会涉及到 init_state = lstm_cell.zero_state (batch_size, dtype=tf.float32)
这里会有 batch_size,感觉导致报错的原因就在这里,请问有其它解决方案吗?
小筑 123 发表于 2018-5-26 17:46:59
具体适用于你的解决方案我给不出来,不好意思,主要是个人对 TF 构建 LSTM 不熟。但确有一个可供参考的思路:楼主的主要问题在于在不同批次间传递了状态,所以状态存储的大小与批次大小有关,需要指定 / 固定,模型构建好了以后不方便更改。对于训练转使用的这个特殊情况,可以使用重建模型并复制变量的办法。在 Keras 架构中,对模型的变量可以取出和导入:用 trained_weights = train_model.get_weights () 取出训练好的变量,然后构建适用于新 batch_size 的
新模型,用 infer_model.set_weights (trained_weights) 导入变量。至于楼主的模型在 TF 下怎么做,我确实无从谈起。如果楼主解决了,希望能分享出来供大家学习,先行谢过!
yunhai_luo 2018-5-27 16:12
batch size 和 time step 都是可以变的,一种方案是新建一个 rnn 和之前的共享参数,利用 variable_scope,我一般是这么干的,另一种是利用 dynamic_rnn 的一个 tf 自带的 wrap,但是我没试过。我记得 tf 官方 rnn 教程里就是用第一种方法的,仔细看看代码肯定能搞定的。
文韬武略 发表于 2018-5-28 10:26:33
yunhai_luo:
如果改变 batch_size(stateful 时)和 time_step 的话会不会改变模型的预测方式和预测能力呢?
2018-5-28 13:39
小筑 123: 回复 yunhai_luo :
本质上是不会变得,因为 RNN 的参数在不同的时间步上是共享的,其次跟 batch_size 没有什么关系
2018-5-29 08:29
小筑 123:
谢谢您提供的一种思路,那个教程其实我之前也看过,是通过模型的复用实现的,在复用模型的时候,给与不同的 batch_size 和 time_steps,但在训练的过程中改变 batch_size 是没法做到的。我实现 rnn 的方式就是通过 dynamic_rnn 实现的,我又仔细看了下 API 的说明,发现其实是可以做到在训练的时候改变 bath_size 的,详细参见下楼。感谢您的回复
2018-5-29 08:32
yunhai_luo: 回复 小筑 123 :
嗯,多谢楼主回复。是不是也就是说 time_step 的设置对于模型预测能力本质上没有影响?当然模型预测能力跟 batch_size 无关应该是意料之中的期望。
2018-5-29 12:51
小筑 123: 回复 yunhai_luo :
我觉得 time_step 更多的是根据你样本的时间序列长度来定的,样本在时间维上有多长,就可以给到多长。但 time_step 太长的话,也会出现问题,虽然说 lstm 具有很强的长时依赖提取能力,但过长会导致训练难度的加大和难以拟合,也会出现梯度爆炸或消失的情况,time_step 是要根据具体问题而定的
2018-5-29 19:30
yunhai_luo: 回复 小筑 123 :
多谢楼主!是我理解 time_step 不足。
2018-5-30 00:07
2018-5-30
with tf.variable_scope ('LSTM_layer'):
convnets = tf.reshape (convnets, shape=[-1, n_timewin, 4*4*128], name='Reshape_for_lstm')
#lstm cell inputs:[batchs, time_steps, hidden_units]
with tf.variable_scope ('LSTM_Cell'):
lstm_cell = tf.contrib.rnn.BasicLSTMCell (num_units=num_units, forget_bias=1.0, state_is_tuple=True)
init_state = lstm_cell.zero_state (batch_size, dtype=tf.float32) # 全初始化为 0state
outputs, final_state = tf.nn.dynamic_rnn (lstm_cell, convnets, initial_state=init_state, time_major=False)
outputs = tf.transpose (outputs, [1,0,2])
outputs = outputs [-1]
这是最开始模型的定义,由于这里对 init_state 进行了 zero 初始化,这里涉及到了 batch_size,这里就是导致后来喂数据的时候,不能改变 bathc_size 的原因,通过查 dynamic_rnn 的 API 说明,它是可以不提供 initial_state,让其自行填充为 0 的,只需要指定 dtype 即可。
将 outputs, final_state = tf.nn.dynamic_rnn (lstm_cell, convnets, initial_state=init_state, time_major=False) 替换成下行即可在训练的过程中改变 batch_size
outputs, final_state = tf.nn.dynamic_rnn (lstm_cell, convnets, dtype=tf.float32, time_major=False)
其实我改变 batch_size 的初衷是,我的训练集不可能刚好是 batch_size 的整数倍,所以最后一个 batch 的样本不得不放弃,或者采取其它的操作对于如何改变时间步,dynamic_rnn 有个参数为 sequence_length,用 feed_dict 给它喂对应 batch 的序列长度就可以了
小筑 123 发表于 2018-5-29 08:40:10
那这样说起来,其他模型是不是也存在这种参数呢?
M 丶 Sulayman 发表于 2018-5-29 15:50:01
不知道你指的其它模型是什么模型,涉及到 rnn 的都需要注意这个问题。纯 CNN 下,bathc_size 随时可以变
小筑 123 2018-5-29 19:31
我记得 dynamic_rnn 是可变的
zhanys_7 发表于 2018-7-3 16:42:37