第一次用 tensorflow 尝试去复现一片论文, 代码比较迅速的写好了,在训练的时候遇到了一些问题在尝试训练的时候,发生 ResourceExhaustedError (see above for traceback): OOM 的错误
当然我也知道这很多情况下是 batch 过大的问题导致的,但我对模型除了参数以外哪里比较耗 gpu 显存没有啥概念,我的 batchsize 一直调到 1 为止我的 model 才 train 的起来,这让我有些困惑
我通过 run_option = tf.RunOptions (report_tensor_allocations_upon_oom = True) 打印了一些信息如下:
[[Node: add_46/_53 = _Recv [client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_3076_add_46", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
Current usage from device: /job:localhost/replica:0/task:0/device:GPU:0, allocator: GPU_0_bfc
450.14MiB from shared_model/unet_01/BiasAdd-0-1-TransposeNCHWToNHWC-LayoutOptimizer
450.14MiB from shared_model/unet_02/BiasAdd-1-1-TransposeNCHWToNHWC-LayoutOptimizer
450.00MiB from shared_model/unet_00/Conv2D
450.00MiB from shared_model/unet_00/BiasAdd-1-1-TransposeNCHWToNHWC-LayoutOptimizer
450.00MiB from shared_model/unet_01/Conv2D
450.00MiB from shared_model/unet_02/Conv2D
450.00MiB from gradients/shared_model/unet_07/Conv2D_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer
239.35MiB from shared_model/unet_07/BiasAdd-0-1-TransposeNCHWToNHWC-LayoutOptimizer
225.70MiB from shared_model/unet_04/Conv2D
225.56MiB from shared_model/unet_04/BiasAdd-1-1-TransposeNCHWToNHWC-LayoutOptimizer
225.00MiB from shared_model/unet_03/BiasAdd-0-1-TransposeNCHWToNHWC-LayoutOptimizer
225.00MiB from shared_model/unet_07/Conv2D
114.60MiB from shared_model/unet_06/Relu-0-1-TransposeNCHWToNHWC-LayoutOptimizer
112.50MiB from shared_model/unet_05/Conv2D
112.50MiB from shared_model/unet_05/BiasAdd-1-1-TransposeNCHWToNHWC-LayoutOptimizer
112.50MiB from shared_model/unet_06/BiasAdd-1-1-TransposeNCHWToNHWC-LayoutOptimizer
63.28MiB from gradients/shared_model/unet_00/Conv2D_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer
Remaining 94 nodes with 29.03MiB
其中可以看到 shared_model/unet_01/BiasAdd-0-1-TransposeNCHWToNHWC-LayoutOptimizer 这一项有 450M 这么大。。我根据我的命名空间仔细对应 tensorboard 里面看了一下,如下图
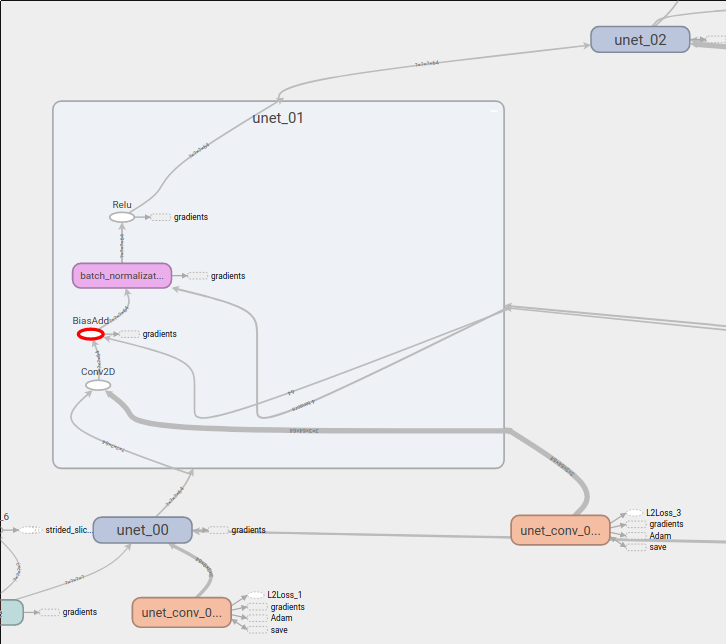
也不知到它究竟对应的是哪个
刚开始写这些东西也不知道自己写对没,关键是为什么这个东西会占用这么大的内存?tensorflow 对每一个位置的 tensor 会
我的网络结构大致如图所示

网络对应代码如下
def flow_estimation_network (input_frames):
"""
Spatio-temporal Flow Estimation Network
Input:
-input_frames: tensor of size (B, H, W, C*T)
Output:
- flow estimation: (B, H, W, 3)
"""
print ("Flow estimation network\n", "Input: input frame with ", input_frames)
H = tf.cast (tf.shape (input_frames)[1], tf.int32)
W = tf.cast (tf.shape (input_frames)[2], tf.int32)
# Assume T = C = 3
input_channels = 9
weights = []
def u_net_layer (layer_id, input, input_channels, output_channels, stride, relu=True):
"""
Used to generate layer for U-net
Architect: conv->bn->relu
"""
with tf.name_scope ("unet_%02d" % layer_id):
conv_w = tf.get_variable ("unet_conv_%02d_w" % layer_id, [3, 3, input_channels, output_channels],\
initializer=tf.random_normal_initializer (stddev=np.sqrt (2.0/9/float (input_channels))))
conv_b = tf.get_variable ("unet_conv_%02d_b" % layer_id, [output_channels], initializer=tf.constant_initializer (0))
weights.append (conv_b)
weights.append (conv_w)
conv_tensor = tf.nn.bias_add (tf.nn.conv2d (input, conv_w, strides=[1, stride, stride, 1], padding="SAME"), conv_b)
conv_tensor = tf.layers.batch_normalization (conv_tensor)
if relu:
return tf.nn.relu (conv_tensor)
else:
return conv_tensor
# Down layers
conv_tensor = u_net_layer (0, input_frames, input_channels, 64, 1)
conv_tensor = u_net_layer (1, conv_tensor, 64, 64, 1)
conv_tensor = u_net_layer (2, conv_tensor, 64, 64, 1)
conv_tensor_2 = conv_tensor
conv_tensor = u_net_layer (3, conv_tensor, 64, 128, 2)
conv_tensor = u_net_layer (4, conv_tensor, 128, 128, 1)
conv_tensor_4 = conv_tensor
conv_tensor = u_net_layer (5, conv_tensor, 128, 256, 2)
conv_tensor = u_net_layer (6, conv_tensor, 256, 256, 1)
# Up layers resize methods:ResizeMethod.BILINEAR
conv_tensor = tf.image.resize_images (conv_tensor, [tf.div (H,2), tf.div (W,2)])
conv_tensor = u_net_layer (7, conv_tensor, 256, 128, 1, relu=False)
conv_tensor = tf.nn.relu (tf.add (conv_tensor, conv_tensor_4))
conv_tensor = u_net_layer (8, conv_tensor, 128, 128, 1)
conv_tensor = tf.image.resize_images (conv_tensor, [H, W])
conv_tensor = u_net_layer (9, conv_tensor, 128, 64, 1, relu=False)
conv_tensor = tf.nn.relu (tf.add (conv_tensor, conv_tensor_2))
conv_tensor = u_net_layer (10, conv_tensor, 64, 64, 1)
conv_tensor = u_net_layer (11, conv_tensor, 64, 3, 1)
print ("Output: ", conv_tensor)
return conv_tensor, weights
def image_process_network (yt, yt_):
"""
yt and yt_ are of (B, H, W, 3)
"""
with tf.name_scope ("res_9"):
# input : [B, H, W, 6]
input_tensor = tf.concat ([yt, yt_], axis=3)
weights = []
tensor = None
conv_00_w = tf.get_variable ("conv_00_w", shape=[3, 3, 6, 64], initializer=tf.random_normal_initializer (stddev=np.sqrt (2.0/9/64)))
conv_00_b = tf.get_variable ("conv_00_b", shape=[64], initializer=tf.constant_initializer (0))
weights.append (conv_00_w)
weights.append (conv_00_b)
tensor = tf.nn.relu (tf.add (tf.nn.conv2d (input_tensor, conv_00_w, strides=[1,1,1,1], padding='SAME'), conv_00_b))
depth = 9
for x in range (depth):
conv_w = tf.get_variable ("conv_%d_w" % (x+1), shape=[3, 3, 64, 64], initializer=tf.random_normal_initializer (stddev=np.sqrt (2.0/9/64)))
conv_b = tf.get_variable ("conv_%d_b" % (x+1), shape=[64], initializer=tf.constant_initializer (0))
weights.append (conv_b)
weights.append (conv_w)
conv_tensor = tf.nn.bias_add (tf.nn.conv2d (tensor, conv_w, strides=[1,1,1,1], padding='SAME'), conv_b)
tensor = tf.nn.relu (tf.add (tensor, conv_tensor))
conv_10_w = tf.get_variable ("conv_10_w", shape=[3, 3, 64, 3], initializer=tf.random_normal_initializer (stddev=np.sqrt (2.0/9/64)))
conv_10_b = tf.get_variable ("conv_10_b", shape=[3], initializer=tf.constant_initializer (0))
weights.append (conv_10_b)
weights.append (conv_10_w)
tensor = tf.nn.bias_add (tf.nn.conv2d (tensor, conv_10_w, strides=[1,1,1,1], padding='SAME'), conv_10_b)
return tensor, weights
jojo23333 2018-9-12 22:23:02