文 / Tom O’ Malley
能否选择良好的超参数,通常是决定机器学习项目成败的关键。随着机器学习领域不断发展成熟,依赖试错法来为这些参数寻找恰当的值(通常戏称为 “Grad Student Descent”)已经无法满足可扩展性的需求。实际上,当今许多最前沿的结果(如 EfficientNet)都是通过复杂的超参数优化算法而得以发现。
Keras Tuner 是一个易于使用的分布式超参数优化框架,能够解决执行超参数搜索时的一些痛点。Keras Tuner 可让您轻松定义搜索空间,并利用内置算法找到最佳超参数的值,内置有贝叶斯优化、Hyperband 和随机搜索算法,其设计亦便于研究人员进行新的搜索算法的扩展。
使用 Keras Tuner 调节超参数的示例,详细代码在下面。
下面是一个简单的端到端示例。首先,我们定义一个模型构造函数。在 hp 中进行超参数采样,例如 hp.Int ('units', min_value=32, max_value=512, step=32) (特定范围内的某个整数)。请注意根据模型构建代码来定义超参数的方式。下方示例中,我们构建了一个简单的可调参模型,并使用 CIFAR-10 进行训练:
import tensorflow as tf
def build_model (hp):
inputs = tf.keras.Input (shape=(32, 32, 3))
x = inputs
for i in range (hp.Int ('conv_blocks', 3, 5, default=3)):
filters = hp.Int ('filters_' + str (i), 32, 256, step=32)
for _ in range (2):
x = tf.keras.layers.Convolution2D (
filters, kernel_size=(3, 3), padding='same')(x)
x = tf.keras.layers.BatchNormalization ()(x)
x = tf.keras.layers.ReLU ()(x)
if hp.Choice ('pooling_' + str (i), ['avg', 'max']) == 'max':
x = tf.keras.layers.MaxPool2D ()(x)
else:
x = tf.keras.layers.AvgPool2D ()(x)
x = tf.keras.layers.GlobalAvgPool2D ()(x)
x = tf.keras.layers.Dense (
hp.Int ('hidden_size', 30, 100, step=10, default=50),
activation='relu')(x)
x = tf.keras.layers.Dropout (
hp.Float ('dropout', 0, 0.5, step=0.1, default=0.5))(x)
outputs = tf.keras.layers.Dense (10, activation='softmax')(x)
model = tf.keras.Model (inputs, outputs)
model.compile (
optimizer=tf.keras.optimizers.Adam (
hp.Float ('learning_rate', 1e-4, 1e-2, sampling='log')),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
下一步,将 Tuner 实例化。您应指定模型的构造函数,以及需要优化的对象名称(对于内置指标,是否进行最小化或最大化可通过自动推理得出;而对于自定义指标,则可通过 kerastuner.Objective 类指定此内容)。在本示例中,Keras Tuner 会使用 Hyperband 算法搜索超参数:
import kerastuner as kt
tuner = kt.Hyperband (
build_model,
objective='val_accuracy',
max_epochs=30,
hyperband_iterations=2)
接下来,我们将使用 TensorFlow Datasets 下载 CIFAR-10 数据集,然后开始超参数搜索。调用 search 方法以开始搜索。该方法与 keras.Model.fit 的签名相同:
import tensorflow_datasets as tfds
data = tfds.load ('cifar10')
train_ds, test_ds = data ['train'], data ['test']
def standardize_record (record):
return tf.cast (record ['image'], tf.float32) / 255., record ['label']
train_ds = train_ds.map (standardize_record).cache ().batch (64).shuffle (10000)
test_ds = test_ds.map (standardize_record).cache ().batch (64)
tuner.search (train_ds,
validation_data=test_ds,
epochs=30,
callbacks=[tf.keras.callbacks.EarlyStopping (patience=1)])
每个模型最多都将接受 30 轮训练,并会经历两次 Hyperband 算法迭代。之后,您可以使用 get_best_models 函数检索在搜索期间发现的最佳模型:
best_model = tuner.get_best_models (1)[0]
您也可查看通过搜索发现的最佳超参数值:
best_hyperparameters = tuner.get_best_hyperparameters (1)[0]
以上就是执行复杂的超参数搜索所需的全部代码!
您可以在 此处 找到上述示例的完整代码。
内置可调参模型
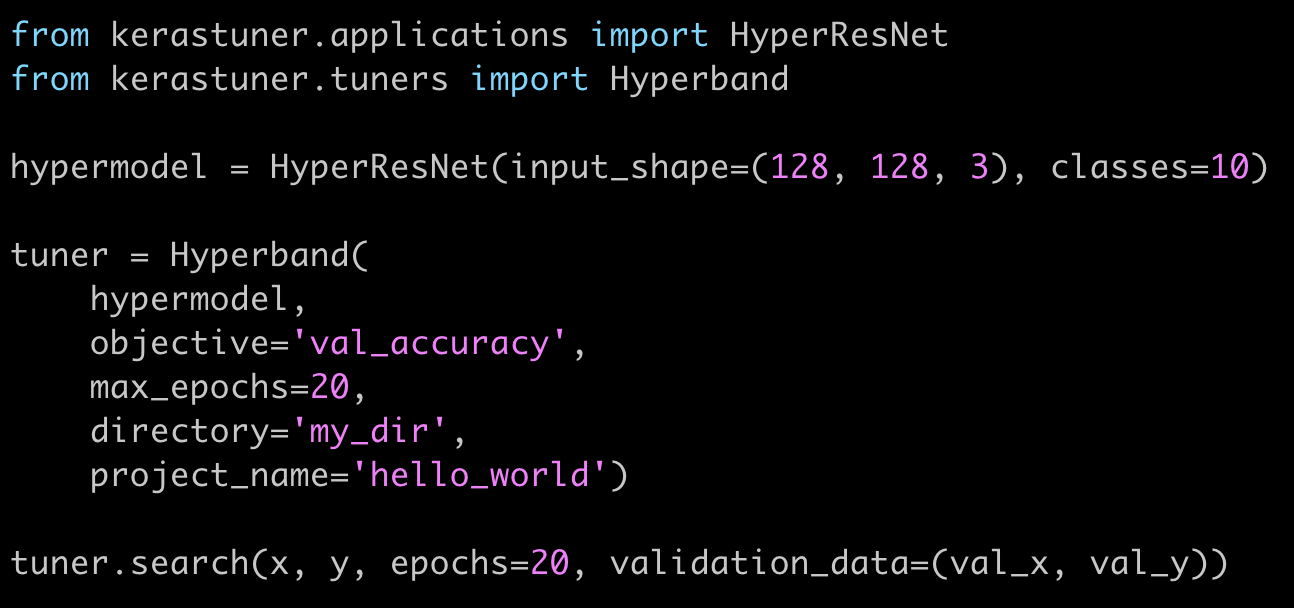
除了可以让您方便定义自己的可调参模型以外,Keras Tuner 还提供两个内置可调参模型:HyperResnet 和 HyperXception。这两个模型会分别搜索 ResNet 和 Xception 架构的各种排列,也可和 Tuner 配合使用,比如:
tuner = kt.tuners.BayesianOptimization (
kt.applications.HyperResNet (input_shape=(256, 256, 3), classes=10),
objective='val_accuracy',
max_trials=50)
分布式调参
借助 Keras Tuner,您将能同时进行数据并行和 trial-parallel 的分布式作业。这意味着您可以使用 tf.distribute.Strategy 在多个 GPU 上运行每个模型,还可以在不同工作线程 (worker) 上并行搜索多个不同的超参数组合。
执行一次并行搜索试验无需修改任何代码。只需设置 KERASTUNER_TUNER_ID 、 KERASTUNER_ORACLE_IP 和 KERASTUNER_ORACLE_PORT 这几个环境变量即可,例如此处的 bash 脚本所示:
export KERASTUNER_TUNER_ID="chief"
export KERASTUNER_ORACLE_IP="127.0.0.1"
export KERASTUNER_ORACLE_PORT="8000"
python run_my_search.py
这些 Tuner 是通过 Oracle 中心服务来协调搜索的,该服务会告知每个 Tuner 接下来要尝试哪些超参数。如需了解更多信息,请参阅我们的 分布式调参指南。
自定义训练循环
您可将 kerastuner.Tuner 类作为子类,以支持高级用法,例如:
- 自定义训练循环(GAN、强化学习等)
- 在模型构造函数之外添加超参数(预处理、数据增强、测试时增强等)
下面是一个简单示例:
class MyTuner (kt.Tuner):
def run_trial (self, trial, ...):
model = self.hypermodel.build (trial.hyperparameters)
score = … # Run the training loop and return the result.
self.oracle.update_trial (trial.trial_id, {'score': score})
self.oracle.save_model (trial.trial_id, model)
如需了解更多信息,请参阅我们的 Tuner 子类化指南。
为 SciKit Learn 模型调参
虽然 Keras Tuner 的命名中包含 “Keras”,但它可以用来调参其他各种机器学习模型。除了专为 Keras 模型内置的 Tuner,Keras Tuner 还提供了可与 Sci-Kit Learn 模型配合使用的内置 Tuner。下方展示了如何使用该 Tuner 的简单示例:
from sklearn import ensemble
from sklearn import linear_model
def build_model (hp):
model_type = hp.Choice ('model_type', ['random_forest', 'ridge'])
if model_type == 'random_forest':
with hp.conditional_scope ('model_type', 'random_forest'):
model = ensemble.RandomForestClassifier (
n_estimators=hp.Int ('n_estimators', 10, 50, step=10),
max_depth=hp.Int ('max_depth', 3, 10))
elif model_type == 'ridge':
with hp.conditional_scope ('model_type', 'ridge'):
model = linear_model.RidgeClassifier (
alpha=hp.Float ('alpha', 1e-3, 1, sampling='log'))
else:
raise ValueError ('Unrecognized model_type')
return model
tuner = kt.tuners.Sklearn (
oracle=kt.oracles.BayesianOptimization (
objective=kt.Objective ('score', 'max'),
max_trials=10),
hypermodel=build_model,
directory=tmp_dir)
X, y = ...
tuner.search (X, y)
如需了解有关 Keras Tuner 的更多信息,请参阅 Keras Tuner 网站 或 Keras Tuner GitHub。Keras Tuner 是一个开源项目,所有开发工作都在 GitHub 上进行。若您想要了解 Keras Tuner 的某些功能,请在 GitHub 开设一个功能请求问题。若您有意贡献代码,请查看我们的 贡献指南,并向我们发送 Pull Request!
![]()
原文:Hyperparameter tuning with Keras Tuner / 译:TensorFlow 公众号