文 / Google 软件工程师 Daniel Smilkov、Nikhil Thorat 和 Ann Yuan
我们很高兴宣布,TensorFlow.js 现在为浏览器和 Node.js 提供 WebAssembly (WASM) 后端!WASM 是 WebGL 后端的替代方案,只需改变很少量的代码,便可实现 CPU 任务的快速执行。它使用 XNNPack 库来加速运算,可帮助提升更多设备的性能,尤其是缺乏 WebGL 支持或 GPU 速度慢的低端移动设备。
安装
可通过两种方式使用新的 WASM 后端:
1、通过 NPM
// Import @tensorflow/tfjs or @tensorflow/tfjs-core
const tf = require ('@tensorflow/tfjs');
// Add the WASM backend to the global backend registry.
require ('@tensorflow/tfjs-backend-wasm');
// Set the backend to WASM and wait for the module to be ready.
tf.setBackend ('wasm').then (() => main ());
此库预设 WASM 二进制文件相对于主 JS 文件定位。如果您使用的是 Parcel 或 Webpack 等打包工具,则可能需要使用我们的 setWasmPath 帮助程序手动指定 WASM 二进制文件的位置:
import {setWasmPath} from '@tensorflow/tfjs-backend-wasm';
setWasmPath (yourCustomPath);
tf.setBackend ('wasm').then (() => {...});
请参阅我们 README 上的 “使用打包工具” 一章了解详情。
2、通过脚本标记
<!-- Import @tensorflow/tfjs or @tensorflow/tfjs-core -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<!-- Adds the WASM backend to the global backend registry -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-wasm/dist/tf-backend-wasm.js"></script>
<script>
tf.setBackend ('wasm').then (() => main ());
</script>
注意:TensorFlow.js 为每个后端定义了一个优先级,并将针对给定环境条件自动选择最佳支持的后端。现在,WebGL 具有最高优先级,其次是 WASM,然后是普通 JS 后端。如要始终使用 WASM 后端,需要显式调用 “tf.setBackend (‘wasm’)”。
演示
查看在 WASM 后端上运行的人脸检测演示(使用 MediaPipe BlazeFace 模型)。有关此模型的详情,请参阅这篇 文章。
为何选择 WASM?
WASM 是一种跨浏览器工作、可移植汇编和兼容 Web 的二进制文件格式,可在 Web 上实现接近原生代码的执行速度。WASM 于 2015 年作为一种新的基于 Web 的二进制文件格式推出,为 C、C++ 或 Rust 等语言编写的程序提供一个编译目标,以便其在 Web 上运行。自 2017 年以来,WASM 已获得 Chrome、Safari、Firefox 和 Edge 的支持,全球 90%设备 都支持 WASM。
性能
对比 JavaScript :对于机器学习任务中常见的数字工作负载,WASM 通常比 JavaScript 快得多。此外,WASM 的原生解码速度比 JavaScript 的解析速度 快 20 倍。由于 JavaScript 是动态类型语言,并且会执行垃圾回收,因此这可能会在运行时导致明显的非确定性速度减缓。此外,现代 JavaScript 库(如 TensorFlow.js)使用诸如 TypeScript 和 ES6 编译器等编译工具,生成的 ES5 代码(以获取广泛浏览器支持)比普通 ES6 JavaScript 的执行速度更慢。
对比 WebGL :对于大多数模型,WebGL 后端的性能仍然优于 WASM 后端,但是 WASM 在超精简模型(小于 3MB 和 60M 的加法和乘法运算)上的速度则更快。在此种情况下,GPU 并行化的益处无法抵消执行 WebGL 着色器的固定开销成本。下文我们会提供查找此行的指南。不过,现已推出用以添加 SIMD 指令的 WASM 扩展方案,允许对多个浮点运算进行矢量化和并行执行。初步测试表明,启用此类扩展可将今天的 WASM 速度提高 2-3 倍。请密切关注其加载至浏览器的情况!TensorFlow.js 也将自动启用该扩展。
可移植性和稳定性
在机器学习领域,数值精度很重要。WASM 原生支持浮点运算,而 WebGL 后端则需要 OES_texture_float 扩展。并非所有设备都支持此扩展,这意味着某些设备(如支持 WASM 的早期移动设备)不支持 GPU 加速的 TensorFlow.js。
此外,GPU 驱动程序可能与特定硬件相关,并且不同的设备也可能存在精度问题。在 iOS 上,GPU 不支持 32 位浮点数,因此我们退回到 16 位浮点数,进而会导致精度问题。在 WASM 中,将始终以 32 位浮点数进行计算,因此在所有设备之间都能实现一致的精度。
为何应该使用 WASM?
一般来说,当模型较小、需要获取广泛设备支持或项目对数值稳定性要求很高时,WASM 都是一个不错的选择。但是,WASM 与我们的 WebGL 后端不匹配。如果您正在使用 WASM 后端并且需要执行操作,请随时在 Github 上提出 。为满足生产用例的需求, 我们认为推理优先于训练支持。对于浏览器中的训练模型,我们建议使用 WebGL 后端。
在 Node.js 中,对于不支持 TensorFlow 二进制文件的设备,或者您不愿意从源代码开始构建,WASM 后端都是非常好的解决方案。
下表所示为在 2018 版 MacBook Pro(Intel i7 2.2GHz,Radeon 555X)上,我们一些在 WebGL、WASM 和普通 JS (CPU) 间正式支持的模型在 Chrome 上的推理时间(以毫秒为单位)。
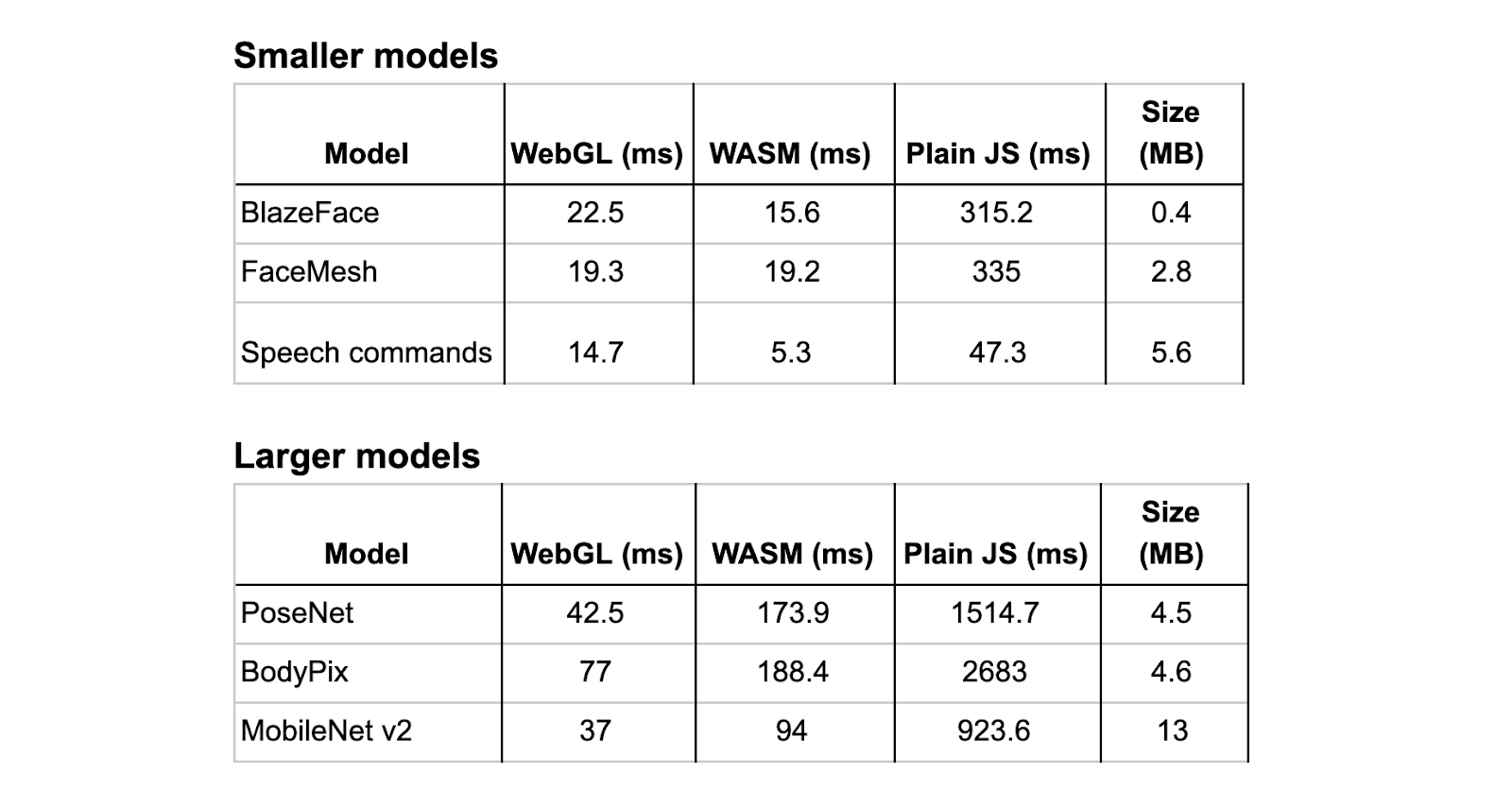
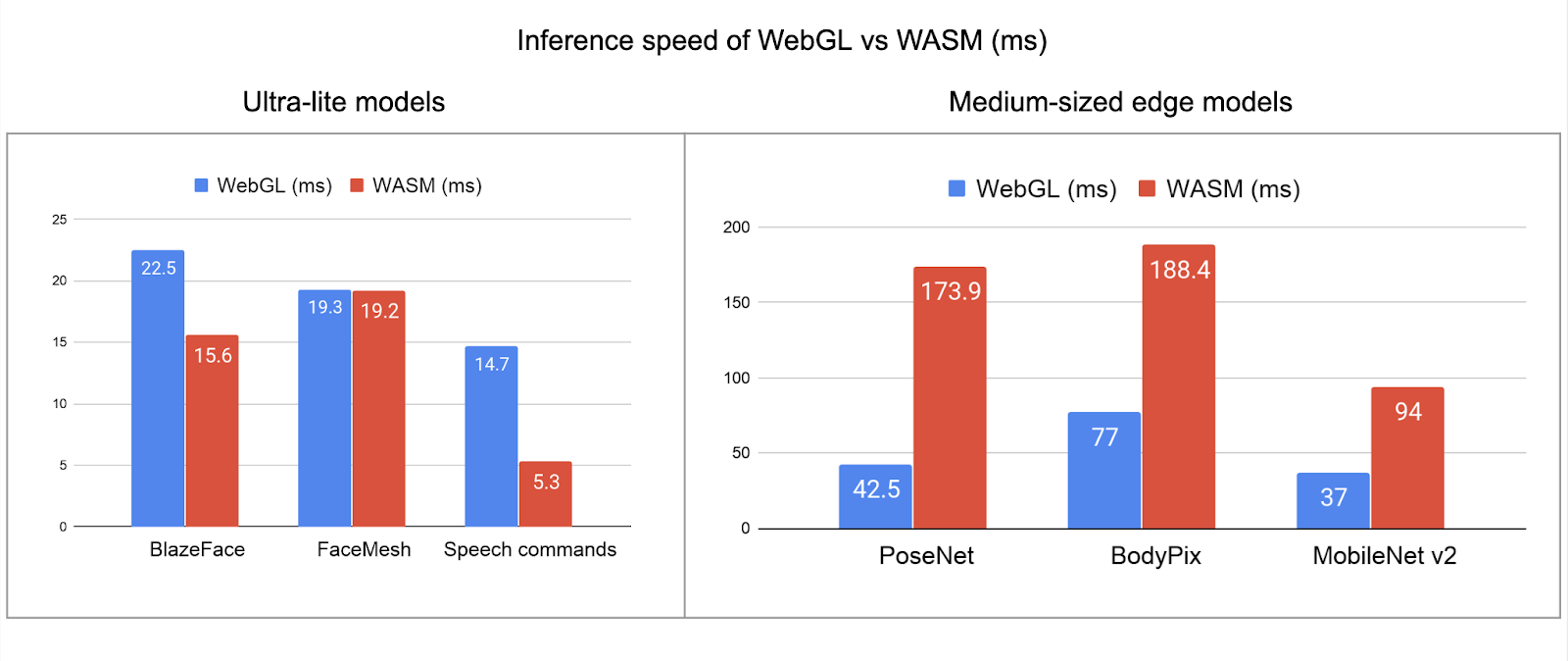
我们观察到,在我们的模型中,WASM 后端比普通 JS(CPU)后端快 10-30 倍。对比 WASM 与 WebGL 可得出两个主要结论:
- 对于类似 MediaPipe 的 BlazeFace 和 FaceMesh 等超轻量级模型,WASM 与 WebGL 速度相当,或比之更快。
- 对于类似 MobileNet、BodyPix 和 PoseNet 的中型边缘模型,WASM 的速度比 WebGL 慢 2-4 倍。
展望未来
我们相信 WASM 后端会越来越受欢迎。去年,我们已经看到一大批为边缘设备设计的高生产质量超轻量级模型(如 MediaPipe 的 BlazeFace 和 FaceMesh),而 WASM 后端非常适合这些模型。
此外,SIMD 和 线程 之类的新扩展也正在积极开发之中,这些扩展将在未来实现进一步的速度提升。
SIMD / QFMA
现在已推出用以添加 SIMD 说明的 WASM 扩展方案。今天,Chrome 已在实验性的状态下部分支持了 SIMD,Firefox 和 Edge 尚在开发之中,而 Safari 尚未给出任何公开信号。SIMD 非常有发展前景。在热门 ML 模型上使用 SIMD-WASM 进行的基准测试表明,速度相比非 SIMD WASM 提高了 2-3 倍。
除了原始的 SIMD 方案外,LLVM WASM 后端近期已 实现对实验性 QFMA SIMD 指令的支持,这将进一步提高内核性能。在热门 ML 模型上进行的基准测试说明,QFMA SIMD 与普通 SIMD 相比,可额外提速 26-50%。
TF.js WASM 后端将通过 XNNPACK 库来使用 SIMD,该库包括已针对 WASM SIMD 优化的 微内核。SIMD 加载后,这些内容将对 TensorFlow.js 用户不可见。
多线程
WASM 规范最近获得了 线程和原子 提议,目的是加快多线程应用程序的速度。此提案目前处于早期阶段,旨在支持发展未来的 W3C 工作组。值得注意的是,Chrome 74+ 已默认启用对 WASM 线程的支持。
线程方案提交后,我们将能够通过 XNNPACK 库充分利用线程,而无需更改 TensorFlow.js 用户代码。
更多信息
- 如您希望了解更多详情,请阅读我们的 WebAssembly 指南。
- 查看 Mozilla 开发者网络的这一资源 系列,了解有关 WebAssembly 的更多信息。
- 感谢您通过 GitHub 上的 issue 和 PR 来提供反馈和做出贡献!
![]()
原文:Introducing the WebAssembly backend for TensorFlow.js
译:TensorFlow 公众号