感谢大佬。
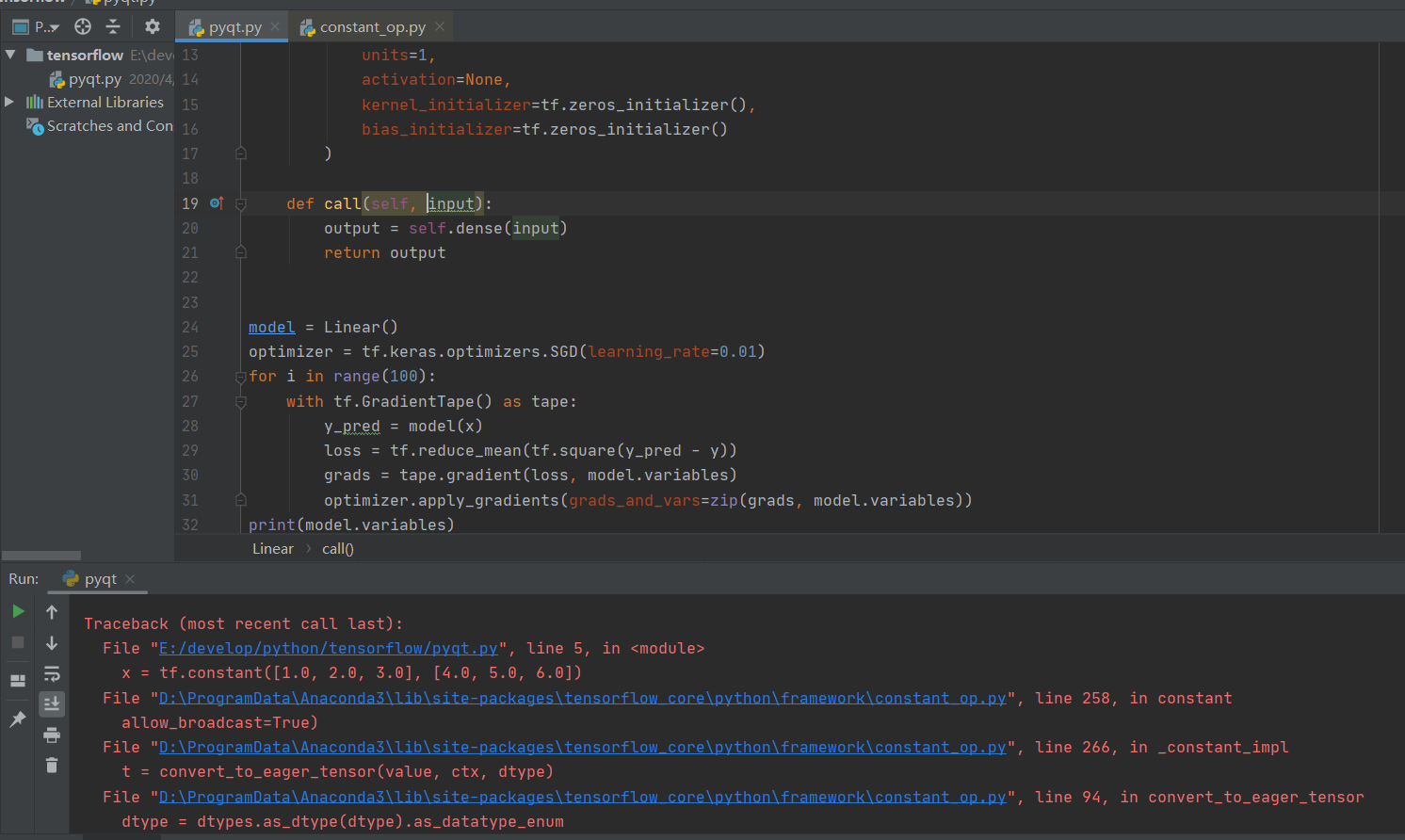
请提供完整的程序代码及报错信息。截图中无法看到完整的 Traceback 信息。
TensorFlow 模型建立与训练 中的代码
import tensorflow as tf
x = tf.constant ([1.0, 2.0, 3.0], [4.0, 5.0, 6.0])
y = tf.constant ([10.0], [20.0])
class Linear (tf.keras.Model):
def init(self):
super ().init()
self.dense = tf.keras.layers.Dense (
units=1,
activation=None,
kernel_initializer=tf.zeros_initializer (),
bias_initializer=tf.zeros_initializer ()
)
def call (self, input):
output = self.dense (input)
return output
model = Linear ()
optimizer = tf.keras.optimizers.SGD (learning_rate=0.01)
for i in range (100):
with tf.GradientTape () as tape:
y_pred = model (x)
loss = tf.reduce_mean (tf.square (y_pred - y))
grads = tape.gradient (loss, model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads, model.variables))
print (model.variables)
错误信息:
D:\ProgramData\Anaconda3\python.exe E:/develop/python/tensorflow/pyqt.py
Traceback (most recent call last):
File “D:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\framework\constant_op.py”, line 92, in convert_to_eager_tensor
dtype = dtype.as_datatype_enum
AttributeError: ‘list’ object has no attribute ‘as_datatype_enum’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “E:/develop/python/tensorflow/pyqt.py”, line 3, in
x = tf.constant ([1.0, 2.0, 3.0], [4.0, 5.0, 6.0])
File “D:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\framework\constant_op.py”, line 258, in constant
allow_broadcast=True)
File “D:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\framework\constant_op.py”, line 266, in _constant_impl
t = convert_to_eager_tensor (value, ctx, dtype)
File “D:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\framework\constant_op.py”, line 94, in convert_to_eager_tensor
dtype = dtypes.as_dtype (dtype).as_datatype_enum
File “D:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\framework\dtypes.py”, line 720, in as_dtype
return _ANY_TO_TF [type_value]
TypeError: unhashable type: ‘list’
X 和 y 的建立过程中少了一层中括号。应该是下面的写法:
X = tf.constant ([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
y = tf.constant ([[10.0], [20.0]])
谢谢。。。。
with tf.GradientTape () as tape:
L = tf.reduce_sum (tf.square (tf.matmul (X, w) + b - y))
w_grad, b_grad = tape.gradient (L, [w, b])
请问这里 L 涉及到一个求和,是如何求得偏导的
这里的求偏导是由 TensorFlow 根据求导的链式法则而自动进行的。求偏导的具体表达式可以参考一下注释 4 和 https://www.math.uwaterloo.ca/~hwolkowi/matrixcookbook.pdf
谢谢回复,我在这里找到了答案
https://blog.csdn.net/li6016265/article/details/86746135
原来是矩阵的链式法则,以前一直不会算矩阵求导我自己却没有发现。
然后如果我没有弄错的话,注释 4 中 a 的偏导最后的 x_i 应该有个转置
学到了,谢谢各位大佬!
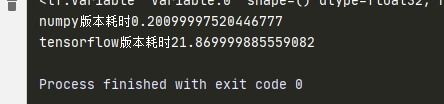
这个例子里为何 tensorflow 比 numpy 版本慢这么多
我这边没有发现这种现象。我猜可能你把 TensorFlow 的各种初始化的时间也算进去了。你可以贴一下你运行的完整代码和系统硬件配置(尤其是 GPU),同时把你的代码贴到 colab 里试试看。

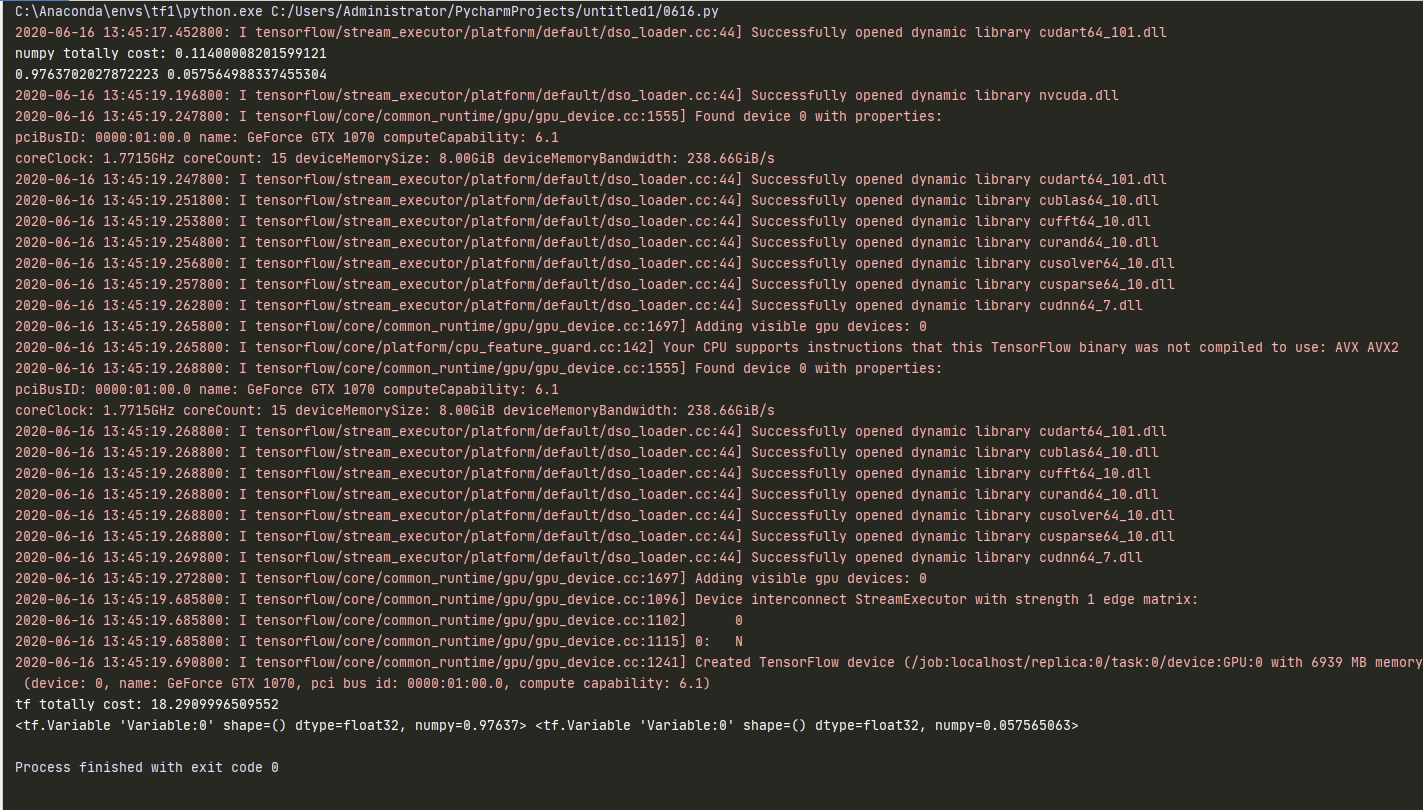
我结合你的代码重新看了一下,确实是有这样的现象。我的理解是,这个例子中的计算相对而言非常简单(只有一个乘法和一个加法),计算量也非常小,所以没能发挥出 TensorFlow 在 GPU 方面的优势。同时每次都自动求导也有额外的开销,肯定不如已经手工写好的求导来得快。在这个例子中,如果我们把数据量增大,例如
X_raw = np.array (range (1, 1000000), dtype=np.float32)
y_raw = np.array (range (1, 1000000), dtype=np.float32)
learning_rate = 5e-7
你会发现 TensorFlow 的速度比 NumPy 快(NumPy 32.12s,TensorFlow 22.73s,Colab GPU 模式)。
链式求导本身我知道,只是题目中对 a b 求导,多个 x y 也叫链式吗
链式求导是指复合函数求导的链式法则,见 https://baike.baidu.com/item/链式法则
都是 warning,前面应该是 numpy 等级高了,可以查一下你 tf 等级对应的 numpy 等级,或者直接进去改。把_np_quint8 = np.dtype ([(“quint8”, np.uint8, 1)]) 改成_np_quint8 = np.dtype ([(“quint8”, np.uint8, (1,))])
写的也太好了吧,看哭了,太牛了!!!
相见恨晚!!!真的写的太好~谢谢大神!!
请问在这里,如果用tensorflow求解梯度,需要自行计算梯度方程吗?还是只需设定损失函数,就可以自行计算梯度?