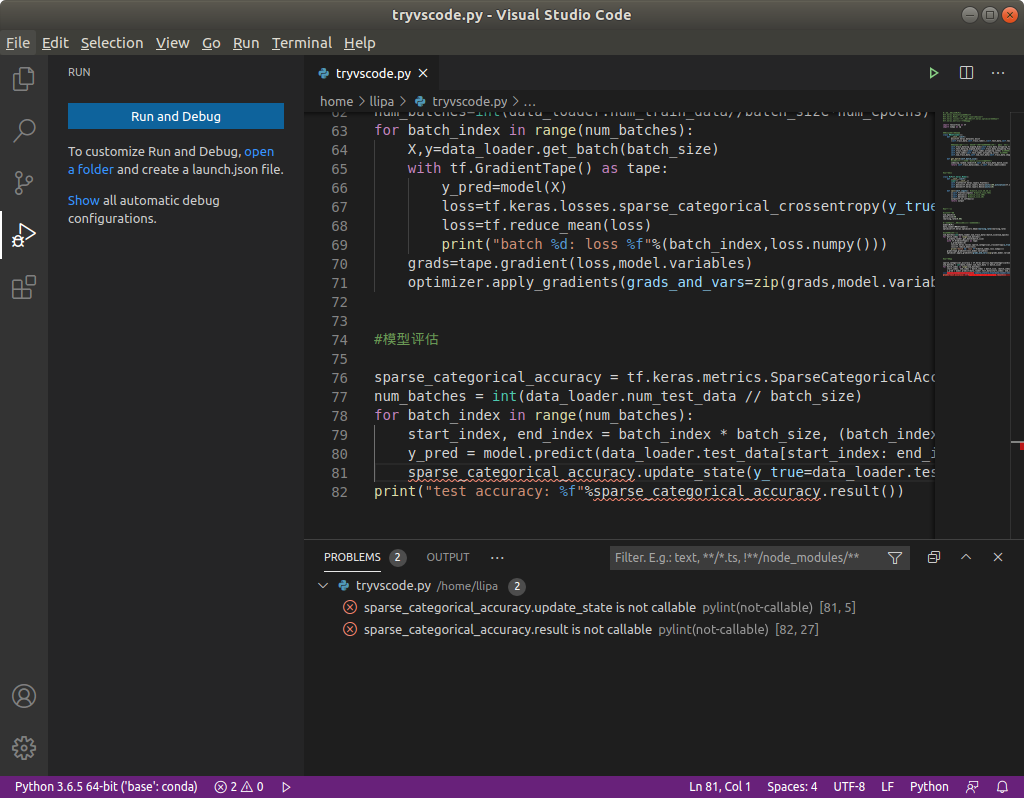
我也是 2.2 版本
代码如下
import tensorflow as tf
import numpy as np
# 数据获取及预处理
class MNISTLoader ():
def __init__(self):
mnist=tf.keras.datasets.mnist
(self.train_data,self.train_label),(self.test_data,self.test_label)=mnist.load_data ()
# 预处理,将图像归一化至 0~1 之间的浮点数,并增加最后一维作为颜色通道
self.train_data=np.expand_dims (self.train_data.astype (np.float32)/255.0,axis=-1) #[60000,28,28,1]
self.test_data=np.expand_dims (self.train_data.astype (np.float32)/255.0,axis=-1) #[10000,28,28,1]
self.train_label=self.train_label.astype (np.int32) #[60000]
self.test_label=self.test_label.astype (np.int32) #[10000]
self.num_train_data,self.num_test_data=self.train_data.shape [0],self.test_data.shape [0]
def get_batch (self,batch_size):
# 从数据集中随即取出 batch_size 个元素并返回
index=np.random.randint (0,self.num_train_data,batch_size)
return self.train_data [index,:],self.train_label [index]
# 模型构建
class MLP (tf.keras.Model):
def __init__(self):
super ().__init__()
self.flatten=tf.keras.layers.Flatten ()
self.dense1=tf.keras.layers.Dense (units=100,activation=tf.nn.relu)
self.dense2=tf.keras.layers.Dense (units=10)
def call (self,inputs): #[batch_size,28,28,1]
x=self.flatten (inputs) #[batch_size,784]
x=self.dense1 (x) #[batch_size,100]
x=self.dense2 (x) #[batch_size,10]
output=tf.nn.softmax (x)
return output
# 模型训练
# 定义超参数
num_epochs=5
batch_size=50
learning_rate=0.001
# 实例化模型和数据读取类,实例化优化器
model=MLP ()
data_loader=MNISTLoader ()
optimizer=tf.keras.optimizers.Adam (learning_rate=learning_rate)
# 获取数据并训练
num_batches=int (data_loader.num_train_data//batch_size*num_epochs)
for batch_index in range (num_batches):
X,y=data_loader.get_batch (batch_size)
with tf.GradientTape () as tape:
y_pred=model (X)
loss=tf.keras.losses.sparse_categorical_crossentropy (y_true=y,y_pred=y_pred)
loss=tf.reduce_mean (loss)
print ("batch %d: loss %f"%(batch_index,loss.numpy ()))
grads=tape.gradient (loss,model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads,model.variables))
# 模型评估
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy ()
num_batches = int (data_loader.num_test_data // batch_size)
for batch_index in range (num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index: end_index])
sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred)
print ("test accuracy: %f"%sparse_categorical_accuracy.result ())
报错如下