楼主你好,在 MLP 模型评估那里的代码报错显示 sparse_categorical_accuracy. update_state 和 result 这两个方法都 is not callable。请问要怎么解决呀
我这边在最新的 TensorFlow 2.2 版本下没有这样的问题。请检查一下你的 TensorFlow 版本,并提供完整代码和完整报错信息。
我也是 2.2 版本
代码如下
import tensorflow as tf
import numpy as np
# 数据获取及预处理
class MNISTLoader ():
def __init__(self):
mnist=tf.keras.datasets.mnist
(self.train_data,self.train_label),(self.test_data,self.test_label)=mnist.load_data ()
# 预处理,将图像归一化至 0~1 之间的浮点数,并增加最后一维作为颜色通道
self.train_data=np.expand_dims (self.train_data.astype (np.float32)/255.0,axis=-1) #[60000,28,28,1]
self.test_data=np.expand_dims (self.train_data.astype (np.float32)/255.0,axis=-1) #[10000,28,28,1]
self.train_label=self.train_label.astype (np.int32) #[60000]
self.test_label=self.test_label.astype (np.int32) #[10000]
self.num_train_data,self.num_test_data=self.train_data.shape [0],self.test_data.shape [0]
def get_batch (self,batch_size):
# 从数据集中随即取出 batch_size 个元素并返回
index=np.random.randint (0,self.num_train_data,batch_size)
return self.train_data [index,:],self.train_label [index]
# 模型构建
class MLP (tf.keras.Model):
def __init__(self):
super ().__init__()
self.flatten=tf.keras.layers.Flatten ()
self.dense1=tf.keras.layers.Dense (units=100,activation=tf.nn.relu)
self.dense2=tf.keras.layers.Dense (units=10)
def call (self,inputs): #[batch_size,28,28,1]
x=self.flatten (inputs) #[batch_size,784]
x=self.dense1 (x) #[batch_size,100]
x=self.dense2 (x) #[batch_size,10]
output=tf.nn.softmax (x)
return output
# 模型训练
# 定义超参数
num_epochs=5
batch_size=50
learning_rate=0.001
# 实例化模型和数据读取类,实例化优化器
model=MLP ()
data_loader=MNISTLoader ()
optimizer=tf.keras.optimizers.Adam (learning_rate=learning_rate)
# 获取数据并训练
num_batches=int (data_loader.num_train_data//batch_size*num_epochs)
for batch_index in range (num_batches):
X,y=data_loader.get_batch (batch_size)
with tf.GradientTape () as tape:
y_pred=model (X)
loss=tf.keras.losses.sparse_categorical_crossentropy (y_true=y,y_pred=y_pred)
loss=tf.reduce_mean (loss)
print ("batch %d: loss %f"%(batch_index,loss.numpy ()))
grads=tape.gradient (loss,model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads,model.variables))
# 模型评估
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy ()
num_batches = int (data_loader.num_test_data // batch_size)
for batch_index in range (num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index: end_index])
sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred)
print ("test accuracy: %f"%sparse_categorical_accuracy.result ())
报错如下
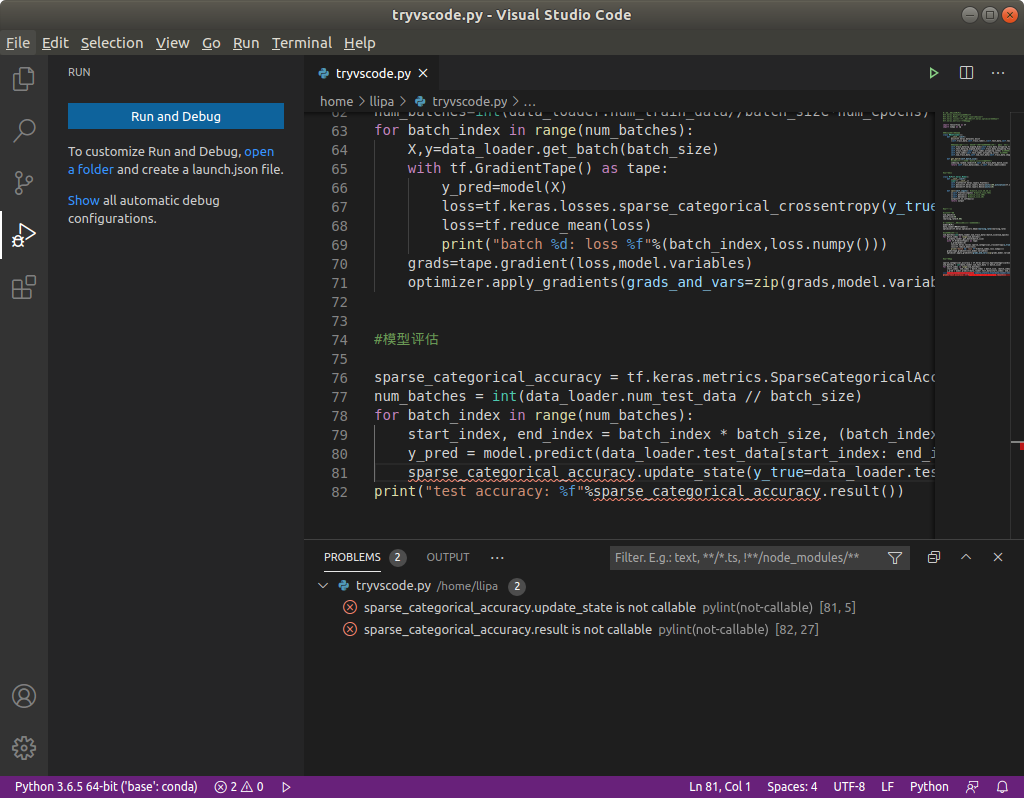
你的代码里的 MNISTLoader 类__init__方法的第三行,把 self.test_data 打成 self.train_data 了
这个改正之后,在 Colab 里是可以直接正常运行的
你这个截图里的错误提示是 pylint 的静态检查,这个可能是 pylint 本身的问题(本手册建议使用 PyCharm 或 Colab 写程序)。报错请以实际运行程序时的报错为准。
感谢博主,问题解决了!修改后的代码在 jupyter notebook 上可以运行了,但是 vscode 依然报一样的错,但也不影响正常运行,我这就去安装 pycharm
再次感谢楼主,vscode 确实是 pylint 出了问题,已找到解决办法!
1 Like
多谢楼主的指导。我碰到了一个保存模型的问题。用文章里的 tf.saved_model.save 存储模型之后,再用 tf.saved_model.load 提取模型再给新的数据 predict 的时候,报错
Expected these arguments to match one of the following 4 option (s):
Option 1:
Positional arguments (3 total):
* TensorSpec (shape=(None, 72, 72, 5), dtype=tf.float32, name=‘input_1’)
* False
* None
Keyword arguments: {}
我去查了也有人出过这种问题,然后安装了 tb-nightly2.1 这个安装包就解决了。但是我这里安装完 tb-nightly2.4 (只能找到最新的)之后,这个问题还是没有解决。请问楼主有什么建议么?谢谢
请提供完整可复现的最小可运行程序代码
问题已经解决了。多谢您的回复。我发现我给的 training data 是 float64 的,但是 layer 的属性是 float32。虽然可以正常去做训练,但是要是用 float64 的数据做 predict 就会报我提到的错误。
不过我还有一个问题,我们在做多分类器训练的时候,丢进去的训练集都是有正确标签的图片,可是并没有空白或其他的图片。例如做猫狗兔训练集的时候,并没有丢给模型猴子的图片。当我对猴子图片或者大海,大山图片做 predict 的时候,这个猫狗兔训练集给出那个 predict 都不对啊。这种情况怎么办?
谢谢
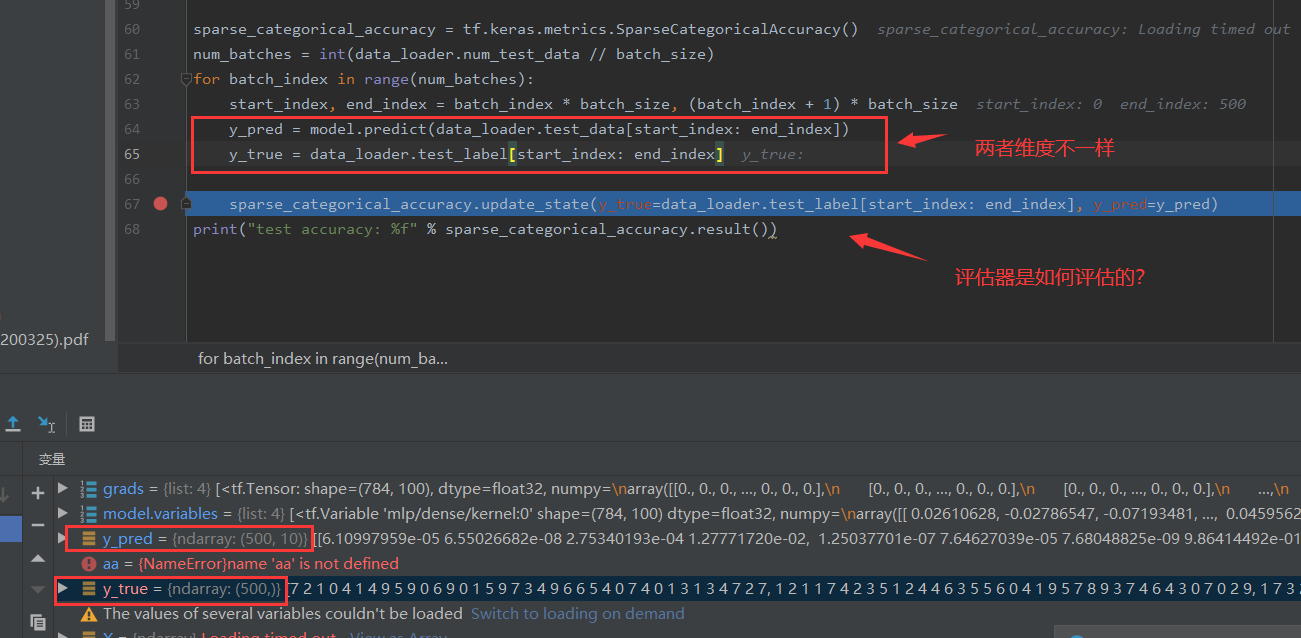
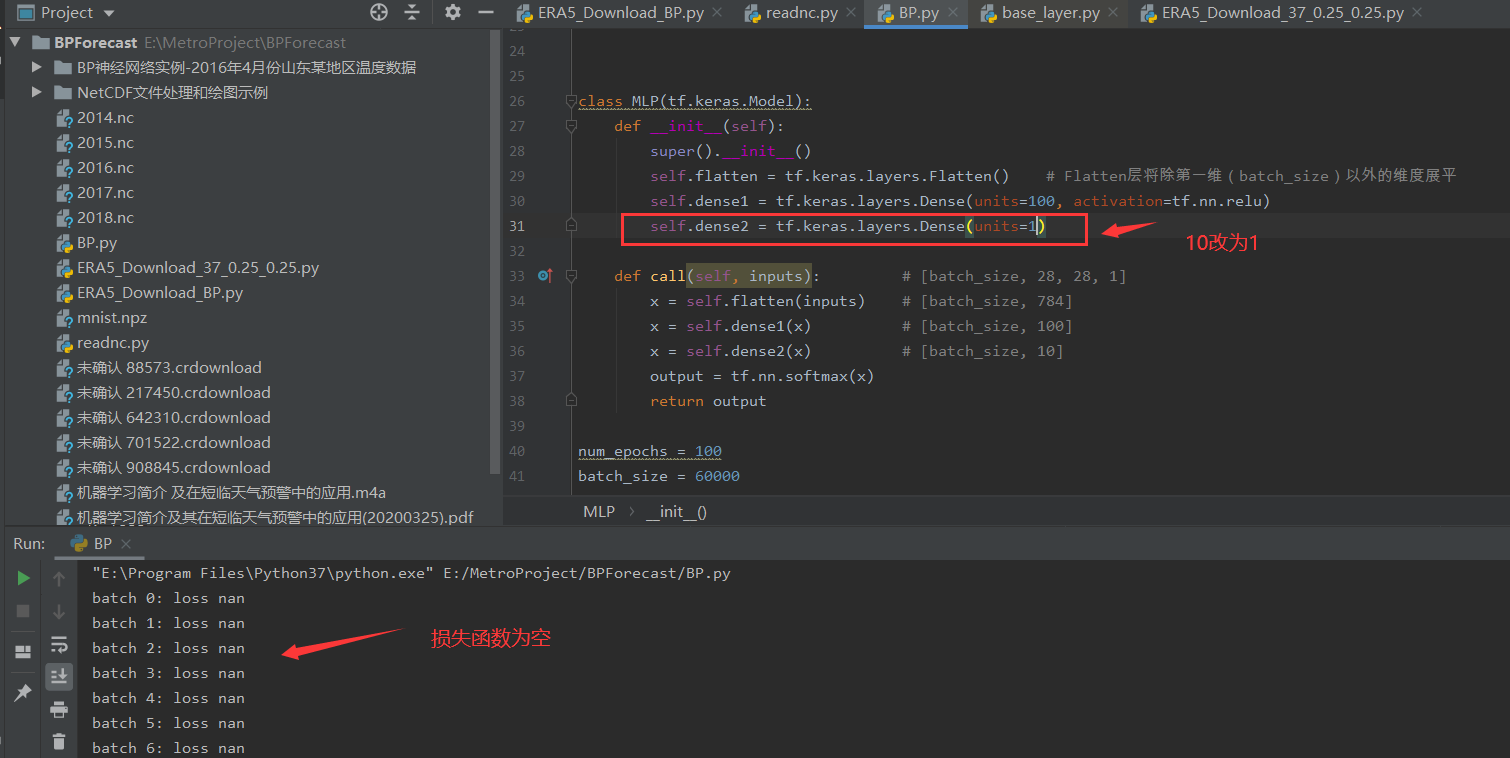
你好,这里的评估器将 y_pred 取 argmax,然后和 y_true 的标签比较,可参考 https://tf.wiki/zh_hans/basic/models.html#id27 里的重实现。这是一个手写数字识别的十分类问题,所以输出层的维度必须为 10,以输出模型预测的 “输入数字分别属于 0~9 的概率”,把输出层改为 1 会导致整个模型失去意义。
哦哦,原来是这样,他的索引值等于他的标签值这就说明预测对了,这里我还有几个问题想问一下:
1.不管实际意义,理论上输出 1 个维度也是可以的,但这里报 nan 的信息,是不是在定义 NLP 类时 output = tf.nn.softmax (x) 这里的问题?
2.初始化阈值和权值只能在 tf.keras.layers.Dense 里使用 kernel/bias_initializer 对该层生效,有没有对整个 model 里的所有层生效的方法?
3.假如我构建含很多个隐藏层的方法,不可能在定义 NLP 类时一个一个去定义层,想过用循环写,但是层的变量名是动态的,这好像不太好实现,请问还有更便捷的方法吗?
在运行模型评估 tf.keras.metrics 报错 ValueError: Structure is ascalarbutlen (flat_sequence)==0>1。
请问有人也遇到这种情况吗?该怎么解决?
您好,我也遇到了这个问题;
我觉得是教程编排的问题,这个 predict 函数本质上应该是 RNN 类内的 一个函数,然后排版中单独放在了评估前面,这样是很容易产生误解的【小白直接复制没过脑子】
希望可以把这个函数按照提供的代码一致,移回到 RNN 类的定义中,或者可以写一个注意~ ;)
这里确实有些没写清楚。我增加了一个说明,并同时给代码增加了一些注释,感谢提醒~
1 Like
模型的训练: tf.keras.losses 和 tf.keras.optimizer
定义一些模型超参数:
num_epochs = 0.1 batch_size = 50 learning_rate = 0.001
这里的 num_epochs 可以设置成 0.1,感觉有点问题
不好意思之前改了一下用来调试忘了改回去,已修正
class CNN 里面 [28 , 28] 通过感受野 [5, 5] 和 pool1 里面的strides = 2, 那么卷积之后的输出应该是个 [12, 12] 的吧?而不是 call 里面注释后面的 # [batch_size, 14, 14, 32]
@snowkylin
可以在Eager模式下运行代码debug看一下。这里的padding设置为same,应该卷积完之后还是28*28。
1 Like