请提供您所使用的代码及出错的位置(代码的第几行)
老师,我在官网上下载了 flower_photos.tgz 数据集文件,请问一下该把这个数据集放在哪个文件夹下,然后使用 dataset = tfds.load (“tf_flowers”, split=tfds.Split.TRAIN, as_supervised=True) 就可以加载数据呀?
楼主您好,在 MNIST 数据集中,您在建好模型进行模型评估的时候有这么两句:
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index: end_index])
这里 batch_size 是 50,也就是说您每次在 predict 的时候,用了 50 个样本,那么这 50 个样本它们是一个样本计算一个偏差,最后把这 50 个偏差给叠加起来,还是一次性的将 50 个样本作为模型的一个输入,来得到一个偏差?
这个地方不是很懂,因为我在机器学习中,每次 predict 的时候都是单样本作为输入
@Wiiki70450 TensorFlow Datasets 的 tf_flowers 数据集是从 GCS(Google Cloud Storage)上下载的预处理后的数据集。 flower_photos.tgz 仅是预处理前的原始数据集文件,并无法直接使用 tfds.load 加载(可以使用 tf.data 自己处理,仿照教程中给出的 cats_vs_dogs 示例)。如果谁发现了好的手动下载数据集并载入的方法,欢迎告诉我。目前来看,在国内使用 TensorFlow Datasets 最省事的方法还是设置代理。TFDS 默认的数据文件夹为 用户目录 /tensorflow_datasets 。例如在 windows 下是 C:\Users\用户名\tensorflow_datasets 。
@shuhaojie 一次性将 50 个样本作为模型的输入,得到 50 个预测值,分别对应于 50 个样本。
那这种方式,和每次将一个样本作为模型的输入,每次得到一个预测值,50 次得到 50 个预测值。这两种方式,除了前面这种方式速度更快,还有没有其他的不同?
原则上来讲,在预测阶段,批量输入只是会更快而已,你也可以一个一个地输入。
ok,谢谢。昨天你回复我之前,我尝试过将每次的输入样本数改为 1 个,得到的准确率和 50 个输入样本基本一样。后来输入样本数改为 25 个,结果得到的准确率是 0.96。
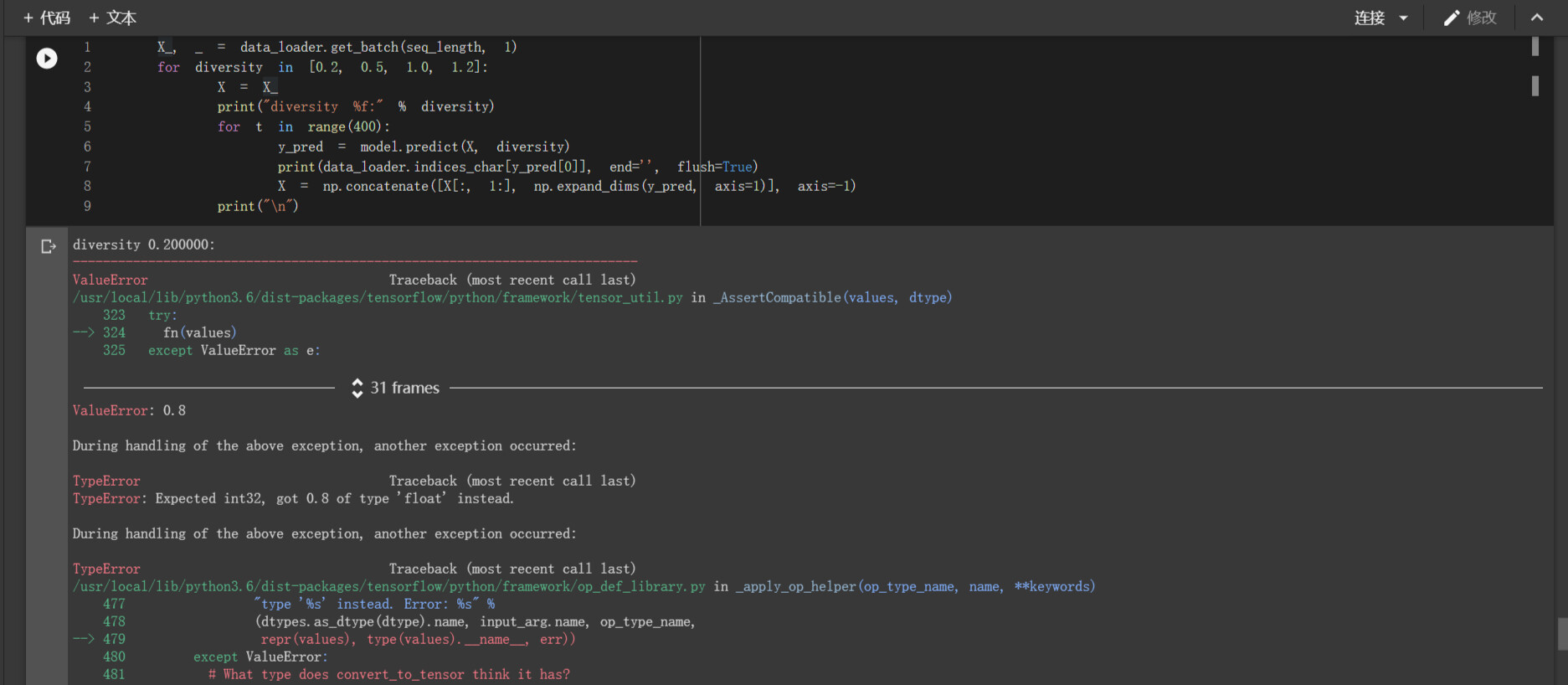
检查一下你的代码是否与 tensorflow-handbook/rnn.py at master · snowkylin/tensorflow-handbook · GitHub 一致,尤其是 RNN 模型类的 predict 方法是否存在。
好的,十分感谢!
@snowkylin 请问设置 HTTPS_PROXY 的这个代理文件在哪里呢?另外,如果把文件下载到本地,“http:// 代理服务器 IP:端口” 这部分怎么填呢?
这就属于 “不适宜公开讨论” 的范畴了,建议请教身边的经常上外网的小伙伴。
各们大神:
在多层感知机(MLP)的数据预准备环节中

此处的 index 的 type 是一个数组,随机取 batch_size 个样本来训练,便是下面 return 中 train_data 应是也是一个数组,self.train_data [index, :] 一个数组中取一此数组怎么能操作。 请各位大神赐教。
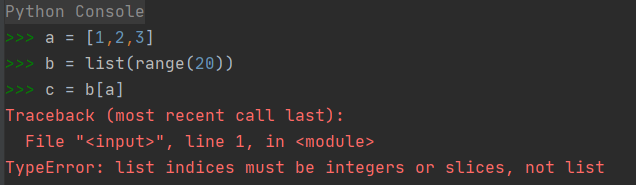

下面评估数据中,那个取数能理解。
这里的train_data不是一般的 Python 数组(list),而是 NumPy 数组。NumPy 数组支持各种高级 slicing 操作,请参考 https://numpy.org/doc/1.18/reference/arrays.indexing.html#integer-array-indexing
噢,明白,我用 np 试一下。谢谢大神!
你好,MLP 模型训练中每个 batch 都调用 getbatch 方法,产生 batch_size 个的随机数据,这样每次不是会有重复的吗??
请参考 11.5. 小批量随机梯度下降 — 动手学深度学习 2.0.0 documentation 。这里用了重复采样(所以会有你说的 “重复” 现象)只是为了实现的方便,其实也可以使用不重复采样。正如引文中所说:
我们可以通过重复采样(sampling with replacement)或者不重复采样(sampling without replacement)得到一个小批量中的各个样本。前者允许同一个小批量中出现重复的样本,后者则不允许如此,且更常见。
请问为什么我的 CNN 训练结果的准确度只有 0.27 呢?
请提供你写的代码。
class CNN (tf.keras.Model):
def __init__(self):
super ().__init__()
self.conv1 = tf.keras.layers.Conv2D (
filters=32,
kernel_size=[5,5],
padding='same',
activation=tf.nn.relu
)
self.pool1 = tf.keras.layers.MaxPool2D (pool_size=[2,2],strides=2)
self.conv2 = tf.keras.layers.Conv2D (
filters=64,
kernel_size=[5,5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D (pool_size=[2,2],strides=2)
self.flatten = tf.keras.layers.Reshape (target_shape=(7*7*64,))
self.dense1 = tf.keras.layers.Dense (units=1024,activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense (units=10)
def call (self,inputs):
x = self.conv1 (inputs)
x = self.pool1 (x)
x = self.conv2 (x)
x = self.pool2 (x)
x = self.flatten (x)
x = self.dense1 (x)
x = self.dense2 (x)
output = tf.nn.softmax (x)
return output
class MNISTLoader ():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data,self.train_label),(self.test_data,self.test_label) = mnist.load_data ()
self.train_data = np.expand_dims (self.train_data.astype (np.float32) / 255.0,axis=-1)
self.test_data = np.expand_dims (self.test_data.astype (np.float32) / 255.0,axis=-1)
self.train_label = self.train_label.astype (np.int32)
self.test_label = self.test_label.astype (np.int32)
self.num_train_data,self.num_test_data = self.train_data.shape [0],self.test_data.shape [0]
def get_batch (self,batch_size):
index = np.random.randint (0,np.shape (self.train_data.shape)[0],batch_size)
return self.train_data [index,:],self.train_label [index]
num_epochs = 5
batch_size = 50
learning_rate = 0.001
model = CNN ()
data_loader = MNISTLoader ()
optimizer = tf.keras.optimizers.Adam (learning_rate=learning_rate)
num_batches = int (data_loader.num_train_data//batch_size*num_epochs)
for batch_index in range (num_batches):
X,y = data_loader.get_batch (batch_size)
with tf.GradientTape () as tape:
y_pred = model (X)
loss = tf.keras.losses.sparse_categorical_crossentropy (y_true=y,y_pred=y_pred)
loss = tf.reduce_mean (loss)
print ("batch %d: loss %f" % (batch_index,loss.numpy ()))
grads = tape.gradient (loss, model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads, model.variables))
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy ()
num_batches = int (data_loader.num_test_data//batch_size)
for batch_index in range (num_batches):
start_index,end_index = batch_index * batch_size,(batch_index+1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index:end_index])
sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index:end_index],y_pred=y_pred)
# sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred)
print ("test accuracy: %f" % sparse_categorical_accuracy.result ())