MNISTLoader的get_batch方法第一行你多打了个 “.shape”……
下面的是正确写法
index = np.random.randint (0, np.shape (self.train_data)[0], batch_size)
或者
index = np.random.randint (0, self.num_train_data, batch_size)
MNISTLoader的get_batch方法第一行你多打了个 “.shape”……
下面的是正确写法
index = np.random.randint (0, np.shape (self.train_data)[0], batch_size)
或者
index = np.random.randint (0, self.num_train_data, batch_size)
非常感谢,问题解决了
请问在用 tfds.load 加载数据集时显示 ValueError: Parsing builder name string tf.flowers failed.
The builder name string must be of the following format:
dataset_name [/config_name][:version][/kwargs],然后看你后面说是设置 HTTPS_PROXY 环境变量,请问如何得到代理服务器 IP 和端口呢?
你把tf_flowers打成了tf.flowers,这是报错的原因。
代理服务器 IP 和端口属于不适合公开讨论的范畴。建议咨询身边经常关注国外信息的小伙伴,或者有条件的话使用 Colab。
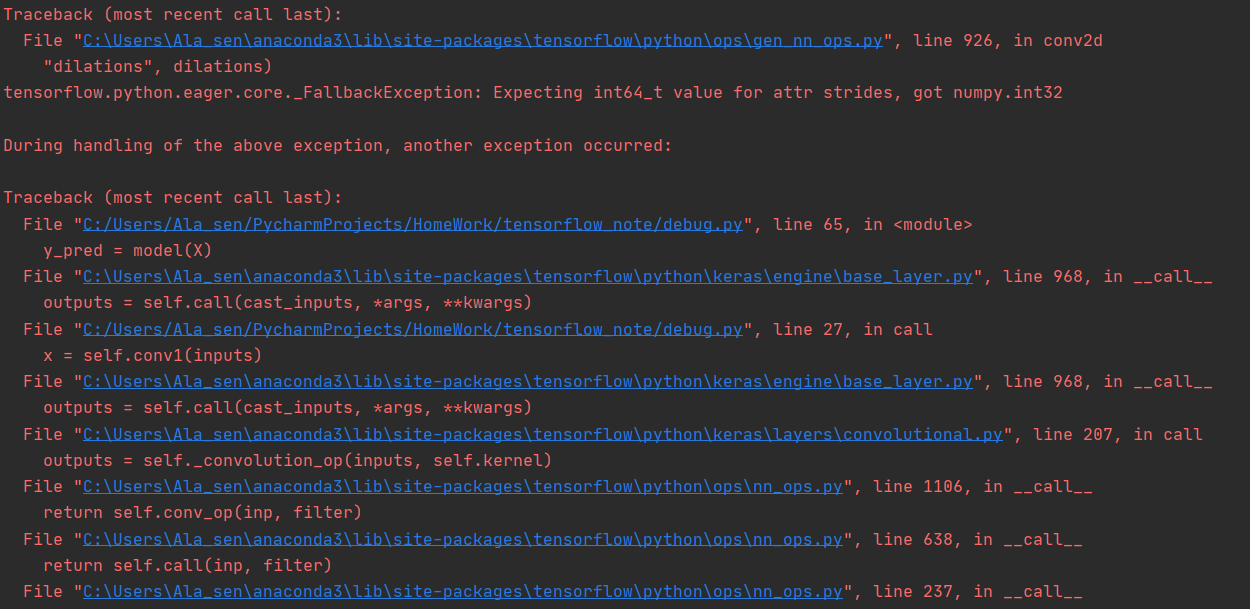
“这个修正后的代码” 指的是哪个代码,请说明或者把这段代码贴出来。看起来是 “一个需要 int64 的地方用了 int32” 的类型问题。
你好,是楼上的 CNN 代码,
import tensorflow as tf
import numpy as np
class CNN (tf.keras.Model):
def __init__(self):
super ().__init__()
self.conv1 = tf.keras.layers.Conv2D (
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding 策略
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPooling2D (pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D (
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPooling2D (pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape (target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense (units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense (units=10)
def call (self, inputs):
x = self.conv1 (inputs) # [batch_size, 28, 28, 32]
x = self.pool1 (x) # [batch_size, 14, 14, 32]
x = self.conv2 (x) # [batch_size, 14, 14, 64]
x = self.pool2 (x) # [batch_size, 7, 7, 64]
x = self.flatten (x) # [batch_size, 7 * 7 * 64]
x = self.dense1 (x) # [batch_size, 1024]
x = self.dense2 (x) # [batch_size, 10]
output = tf.nn.softmax (x)
return output
class MNISTLoader:
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data ()
self.train_data = np.expand_dims (self.train_data.astype (np.float32) / 255, axis=-1)
self.test_data = np.expand_dims (self.test_data.astype (np.float32) / 255, axis=-1)
self.train_label = self.train_label.astype (np.int32)
self.test_label = self.test_label.astype (np.int32)
self.num_train_data, self.num_test_data = self.train_data.shape [0], self.test_data.shape [0]
print (self.num_train_data, self.num_test_data)
def get_batch (self, batch_size):
index = np.random.randint (0, self.num_train_data, batch_size)
return self.train_data [index, :], self.train_label [index]
if __name__ == '__main__':
num_epochs = 5 # 1 个 epoch 表示过了 1 遍训练集中的所有样本
batch_size = 50 # 一次迭代使用的样本量
learning_rate = 0.001
model = CNN ()
data_loader = MNISTLoader ()
optimizer = tf.keras.optimizers.Adam (learning_rate=learning_rate)
num_batches = int (data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range (num_batches):
X, y = data_loader.get_batch (batch_size)
with tf.GradientTape () as tape:
y_pred = model (X)
# 交叉熵作为损失函数
loss = tf.keras.losses.sparse_categorical_crossentropy (y_true=y, y_pred=y_pred)
loss = tf.reduce_sum (loss)
print ('batch %d: loss %f' % (batch_index, loss.numpy ()))
grads = tape.gradient (loss, model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads, model.variables))
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy ()
num_batches = int (data_loader.num_test_data // batch_size)
for batch_index in range (num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index: end_index])
sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred)
print ('test accuracy: %f' % sparse_categorical_accuracy.result ())
下面是完整报错信息,麻烦看一下
我这边在 Colab 里直接运行了一遍代码,并未发现问题。请检查你的 TensorFlow 版本是否为最新的 2.2。如果之前安装过旧版 TensorFlow,建议重新按照 https://tf.wiki/zh_hans/basic/installation.html 配置一遍环境。
调用 predict 的时候,里面调用了 call 方法,call 方法里面每次都是初始化 state,调用
state=self.cell.get_initial_state (batch_size=self.batch_size,dtype=tf.float32) 每次初始化的时候是否能拿到上次训练的 state 呢?如果不能获取之前训练的 state,预测是否没有用到训练的结果呢?
模型的参数(training variable)和 RNN 的初始状态(initial state)是两个不同的东西,模型训练的是前者而不是后者。请参考一下 TensorFlow 模型建立与训练 — 简单粗暴 TensorFlow 2 0.4 beta 文档 “循环神经网络的工作过程” 和 http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/ 以更深入地了解 RNN 的 “状态” 这一概念。
你好,我是装的最新的,运行 MLP 可以,后面的几个神经网络我的都会报相同的错误,我没有另创建 conda 虚拟环境,请问跟这个有关吗?另外,请问怎么查看 cudatoolkit 与 cudnn 已安装的版本?
如果运行 MLP 可以但后面其他的不行,可能说明你的电脑内存或者显卡显存不够。你可以尝试一下调小 batch_size,同时可能也需要参考一下 python 3.x - Tensorflow could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED - Stack Overflow
你好,我的 cpu 为 9 代 i716g,gpu 为 1660ti6g,
我加了如下两句代码后可以了,请问一下这是什么问题
gpu_options = tf.compat.v1.GPUOptions (per_process_gpu_memory_fraction=0.333)
sess = tf.compat.v1.Session (config=tf.compat.v1.ConfigProto (gpu_options=gpu_options))
你好,请问可以在使用 tape.gradient 过程中替换其中的求导函数吗?比如替换其中的 relu 函数,以实现 Guided Backprop,或者说以继承 tf.kreas.Modle 的方式定义模型,以 model (X) 的形式使用它,可以便捷的实现 Guided Backprop 吗?
大神们,调用 MobileNetV2 这一节中,示例的代码没有改变,运行报错,帮我看看错在哪儿?报错如下:
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape [50,96,112,112] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [Op:FusedBatchNormV3]
譬如推荐的这种非 pipeline 的模型,咋使用 callback 呢?
GPU 显存不够,改小 Batch Size 试试。
subclassing 的模型似乎 callback 的意义不大?整个模型都是自定义的,有什么要 callback 的直接写在自定义的模型里就好了。
有道理,谢谢~~
本来是想用那个 early stop 的,不过这样一说倒是自己实现一下也可以的。
没想到作者亲自回复,那必须称赞一下,这绝对是看过的写的最好的 TF2 文档,无论是细节还是整体~