TensorFlow 常用模块
如果程序报错,建议包含以下信息以帮助排除问题:
- TensorFlow 版本(请检查 TensorFlow 版本为 2.0 及以上)
import tensorflow as tf
print (tf.__version__)
- 完整的最小可运行程序代码(建议将代码在 IDE 中运行而不是交互式环境)
- 完整的报错信息(Traceback)
如果程序报错,建议包含以下信息以帮助排除问题:
import tensorflow as tf
print (tf.__version__)
请问一下,from zh ,zh 是什么库,我网上没有查询到
是不是作者自己建的类?
zh 代表本手册的中文注释版源代码目录。前言部分 有提到:
本书的所有示例代码可至 tensorflow-handbook/source/_static/code at master · snowkylin/tensorflow-handbook · GitHub 获得。其中
zh目录下是含中文注释的代码,en目录下是含英文版注释的代码。在使用时,建议将代码根目录加入到PYTHONPATH环境变量,或者使用合适的 IDE(如 PyCharm)打开代码根目录,从而使得代码间的相互调用(形如import zh.XXX的代码)能够顺利运行。
好的,找到了,谢谢~
文档中还是有一些小错误的,有的不仔细研究还挺难发现问题的。
使用传统的 tf.Session 这节中:
sess.run (sparse_categorical_accuracy.update (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred))
应该修改为
sess.run (sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred))
已经合并 pr,可能是这部分代码比较老了没有及时更新。感谢 bug fix。
1.老师,好像在附录里面没有看到关于图执行模式的深入探讨参考资料呀?麻烦确定一下~
2.如果想进一步了解学习 tensorflow 架构设计方面的知识,老师有推荐的资料吗?
雪麒老师,对 tensorflow2.0 的基本开发有一定了解之后,后续是否需要再去学习一下 tensorflow1.X 的使用呀?
如果你接手了什么 TensorFlow 1.X 开发的旧项目又无法升级的话可以学习。总之就是如果用得到(或者不得不用)就去学,否则必要不大。
雪麒老师,保存训练模型时,在命令行输入"–mode=test",显示’–mode’ 不是内部或外部命令,也不是可运行的程序或批处理文件。我查了资料也没搞明白,这是为什么呀?
这里是说在命令行参数中加入 --mode=test 并再次运行代码。也就是说,如果你之前在终端执行代码的指令是
python code.py
那么你现在应该在终端中执行
python code.py --mode=test
明白了,谢谢大佬 ![]() ,终于搞明白这个 argparse 模块了
,终于搞明白这个 argparse 模块了
我发现了一个小错误,应该是读取 “之前” 建立的吧,不是 “之间”
我们可以通过以下代码,读取之间建立的 train.tfrecords 文件,并通过 Dataset.map 方法,使用 tf.io.parse_single_example 函数对数据集中的每一个序列化的 tf.train.Example 对象解码。
笔误已改正,感谢提醒!
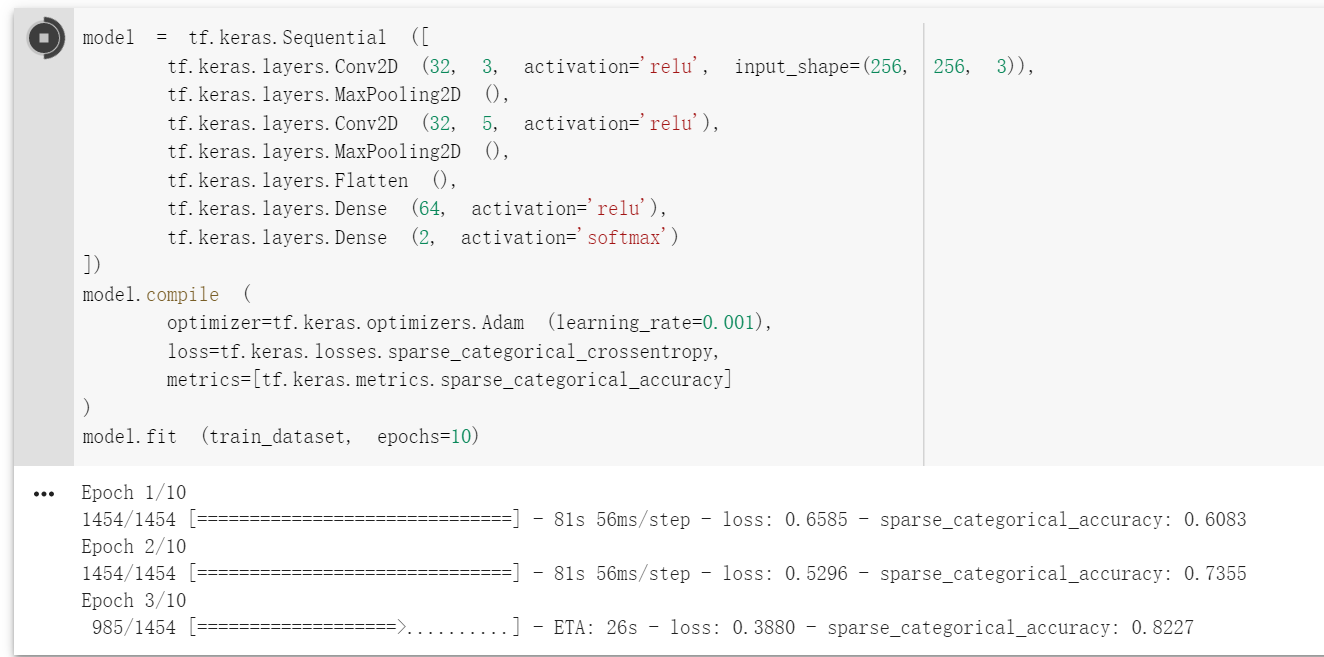
你好! 关于 cats-and-dogs 数据集,我尝试了很多模型,也尝试了文章中的模型,但是 acc 一直在 0.5,应该是完全没有训练出参数,能否帮忙看看是否是哪处 数据处理出错了?代码如下:
import tensorflow_datasets as tfds
import tensorflow as tf
dataset_name = 'cats_vs_dogs'
dataset, info = tfds.load (name=dataset_name, split=tfds.Split.TRAIN, with_info=True)
print (info)
def preprocess (features):
image, label = features ['image'], features ['label']
image = tf.image.resize (image, [256, 256]) / 255.0
return image, label
train_dataset = dataset.map (preprocess).shuffle (23000).batch (32).prefetch (tf.data.experimental.AUTOTUNE)
model = tf.keras.Sequential ([
tf.keras.layers.Conv2D (32, 3, activation='relu', input_shape=(256, 256, 3)),
tf.keras.layers.MaxPooling2D (),
tf.keras.layers.Conv2D (32, 5, activation='relu'),
tf.keras.layers.MaxPooling2D (),
tf.keras.layers.Flatten (),
tf.keras.layers.Dense (64, activation='relu'),
tf.keras.layers.Dense (2, activation='softmax')
])
model.compile (
optimizer=tf.keras.optimizers.Adam (learning_rate=0.001),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit (train_dataset, epochs=10)
我也尝试了用 InceptionV3 做迁移学习,效果都是 0.5,感觉是某块数据集处理上出问题,困扰了我好多天,请大佬帮忙看看,谢谢~