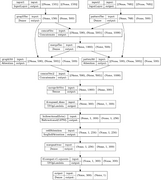
在最近的研究中,我尝试了以下模型来融合这两个特征,然后对它们进行训练和分类。理论上,这种分布式self-attention机制的方法是分别执行两种特征,然后在维度上连接起来,最后输入到模型中进行训练和分类,在本领域也称为cross-attention机制的特征融合。
但是,我们团队通过以下模型的训练得到的分类结果非常非常差。原来这两类特征都是简单的用随机森林分类,分类准确率在92%左右。上图中模型的训练结果只有不到 50% 的训练准确率。
我对这个结果感到非常困惑。也请TensorFlow的专业人士和社区的朋友帮我看看分析一下是不是模型网络有问题,导致学习到的特征信息不足?
非常感谢!期待专业的见解和回复~
图片不清晰可以看下面图片链接:

不知道你的分类任务是什么,如果是二分类的话,50%的准确率几乎是等于随机分类(没有起到效果)的,这种时候多半是模型实现过程中有代码上的错误。如果是从随机森林转换过来的话,建议先使用基础、简单的基于神经网络的分类模型(例如全连接),然后再逐步增加复杂度。除非经验丰富,否则一开始就上自己写的很复杂的网络多半是要出问题的。