
发布人: Shilpa Kancharla
视频数据包含丰富的信息,其结构比图像数据的结构更庞大、更复杂。使用深度学习以节省内存的方式对视频进行分类,可以帮助我们更好地理解数据内容。我们在 tensorflow.google.cn 上发布了一系列教程,介绍了如何加载、预处理和分类视频数据。您可以查阅相关教程进行详细了解:
- 加载视频数据
- 使用 3D 卷积神经网络 (Convolutional Neural Network, CNN) 对视频进行分类
- 用于流式动作识别的 MoViNet
- 使用 MoViNet 和迁移学习 进行视频分类:
在本文中,我们将介绍一些有趣的内容,深入学习部分教程的特定内容,并讨论如何综合运用这些知识构建自有模型,使这些模型可以使用 TensorFlow 以节省内存的方式处理视频或 MRI 扫描等三维数据,如运用 Python 生成器以及调整数据大小或对其进行下采样。
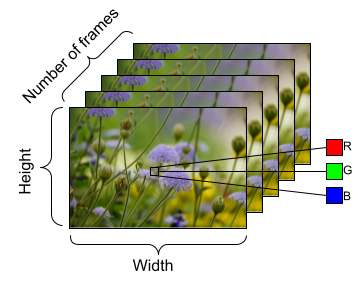
△ 视频数据形状示例,具有以下维度: 帧数 (时间) x 长度 x 宽度 x 通道
使用 FrameGenerator 加载视频数据
在 “加载视频数据” 教程中,我们将借此机会探讨大多数该系列教程的核心部分: FrameGenerator 类。我们可以借助此类得到视频的张量表征,以及视频的标签或类。
class FrameGenerator:
def __init__(self, path, n_frames, training = False):
"""返回一组带有其关联标签的帧。
Args:
path:视频文件路径。
n_frames:帧数。
training:用于确定是否正在创建训练数据集的布尔值。
"""
self.path = path
self.n_frames = n_frames
self.training = training
self.class_names = sorted(set(p.name for p in self.path.iterdir() if p.is_dir()))
self.class_ids_for_name = dict((name, idx) for idx, name in enumerate(self.class_names))
def get_files_and_class_names(self):
video_paths = list(self.path.glob('*/*.avi'))
classes = [p.parent.name for p in video_paths]
return video_paths, classes
def __call__(self):
video_paths, classes = self.get_files_and_class_names()
pairs = list(zip(video_paths, classes))
if self.training:
random.shuffle(pairs)
for path, name in pairs:
video_frames = frames_from_video_file(path, self.n_frames)
label = self.class_ids_for_name[name] # Encode labels
yield video_frames, label
在创建生成器类时,我们会使用函数 from_generator() 将数据提供给我们的深度学习模型。具体而言,from_generator() API 将会创建一个数据集,其内容由生成器生成。使用 Python 生成器比在内存中存储整个数据序列更节省内存。您不妨考虑创建与 FrameGenerator 类似的生成器类,并使用 from_generator() API 将数据加载到 TensorFlow 和 Keras 模型中。
ut_signature = (tf.TensorSpec(shape = (None, None, None, 3),
dtype = tf.float32),
tf.TensorSpec(shape = (),
dtype = tf.int16))
train_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['train'],
10,
training=True),
output_signature = output_signature)
使用 einops 库调整视频数据大小
在第二个视频教程 “使用 3D 卷积神经网络 (Convolutional Neural Network, CNN) 对视频进行分类” 中,我们将讨论如何使用 einops 库,以及如何将其整合到由 TensorFlow 提供支持的 Keras 模型中。该库对于执行灵活的张量操作十分有帮助,并且与 TensorFlow 和 JAX 均可搭配使用。在本教程中该库的作用尤为明显,当数据通过我们创建的 (2+1)D 卷积神经网络时,我们会使用此库调整数据大小。在第二个教程中,我们希望对视频数据进行下采样。下采样之所以十分有用,是因为这项技术可以使我们的模型检查帧的特定部分,以检测可能特定于视频中某个特定特征的模式。借助下采样技术,我们可以舍弃非必要的信息,从而实现降维,进而加快处理速度。
我们使用 einops 库的函数 parse_shape() 和 rearrange()。此处使用的 parse_shape() 函数可将轴的名称映射到其相应的长度。然后该函数会返回包含此信息的字典,名为 old_shape。接下来,我们会使用 rearrange() 函数,以便重新排列多维张量的轴。将张量和要重新排列的轴的名称传递给该函数。
此处的 b t h w c -> (b t) h w c 符号表示我们希望将批次大小 (以 b 表示) 和时间 (以 t 表示) 维度压缩到一起,以将这些数据传递到 Keras Resizing 层对象中。当我们实例化 ResizeVideo 类时,会传入希望在调整帧大小时达到的目标长度和宽度值。完成这项调整操作后,我们会再次使用 rearrange() 函数来将批次大小和时间维度展开 (使用 (b t) h w c -> b t h w c 符号)。
class ResizeVideo(keras.layers.Layer):
def __init__(self, height, width):
super().__init__()
self.height = height
self.width = width
self.resizing_layer = layers.Resizing(self.height, self.width)
def call(self, video):
"""
使用 einops 库调整张量的大小。
Args:
video:视频的张量表征,以一组帧的形式呈现。
Return:
视频的下采样尺寸,根据调整大小时应达到的目标高度和宽度而定。
"""
# b 表示批次大小、t 表示时间、h 表示高度、
# w 表示宽度、c 表示通道数。
old_shape = einops.parse_shape(video, 'b t h w c')
images = einops.rearrange(video, 'b t h w c -> (b t) h w c')
images = self.resizing_layer(images)
videos = einops.rearrange(
images, '(b t) h w c -> b t h w c',
t = old_shape['t'])
return videos
未来计划
以上只是利用 TensorFlow 以节省内存的方式处理视频数据的几种方法,但这些技术并非只能用于视频数据。MRI 扫描等医疗数据或 3D 图像数据也需要高效的数据加载,且可能需要调整数据形状的大小。在计算资源有限的情况下,这些技术对于处理数据而言十分有用。希望这些教程对您有所帮助,感谢阅读!欢迎您持续关注我们,及时获悉更多资讯。
![]()
原文:Using TensorFlow for Deep Learning on Video Data
中文:TensorFlow 公众号