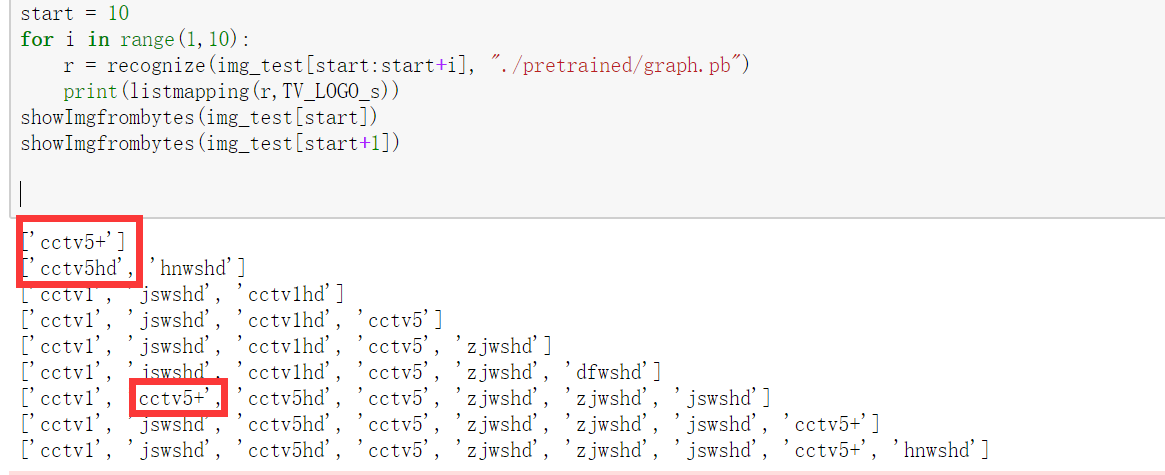
你好,对于引用模型不需要初始化变量的观点是正确的,我已经改正,但是注释掉这两句话并不会对结果有任何影响。还是不对的。为了方便大神们帮我看问题,我将数据集换成了 minst,发现有类似的结果,我将所有代码都上传上来。麻烦帮我看下,包括模型,以及 pb 文件保存方法 1.建立并训练模型,保存 checkpoint
import numpy as np
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets (r"D:\MachineLearning\minst", one_hot=True)
def batch_normal (Y,offset_Beta,scale_J,iteration):
exp_moving_avg = tf.train.ExponentialMovingAverage (0.998, iteration) # adding the iteration prevents from averaging across non-existing iterations
mean, variance = tf.nn.moments (Y, [0])
update_moving_averages = exp_moving_avg.apply ([mean, variance])
m = exp_moving_avg.average (mean)
v = exp_moving_avg.average (variance)
# Ybn = tf.nn.batch_normalization (Y, m, v, offset_Beta, scale_J, 1e-5)
Ybn = tf.nn.batch_normalization (Y, mean, variance, offset_Beta, scale_J, 1e-5)
return Ybn,update_moving_averages
def hidden_layer (X, sizeOutput, iteration = 10, non_linear_name = '',enable_bn=False):
sizeInput = X.shape [1]
W = tf.Variable ( tf.truncated_normal ([int (sizeInput),int (sizeOutput)],stddev=0.001) )
if enable_bn:
Z = tf.matmul (X,W) #In bach norm, the bias B can be ommited due to the offset
scale_J = tf.Variable (tf.ones ([int (sizeOutput)]))
offset_Beta = tf.Variable (tf.zeros ([int (sizeOutput)]))
Y, update_moving_averages = batch_normal (Z,offset_Beta,scale_J, iteration)
else:
B = tf.Variable (tf.zeros ([1,sizeOutput]))
Y = tf.matmul (X,W) + B
if non_linear_name == '': return Y,0
elif non_linear_name == 'softmax': A = tf.nn.softmax (Y)
elif non_linear_name == 'relu': A = tf.nn.relu (Y)
elif non_linear_name == 'sigmoid': A = tf.nn.sigmoid (Y)
return A, update_moving_averages
#X = tf.placeholder (tf.float32, [None, 96*35],name = 'Input')
#Y_LABEL = tf.placeholder (tf.float32, [None, CLASSES], name = 'Label')
X = tf.placeholder (tf.float32, [None, 28*28],name = 'Input')
Y_LABEL = tf.placeholder (tf.float32, [None, 10], name = 'Label')
lr = tf.placeholder (tf.float32, name = 'LearningRate')
iters = tf.placeholder (tf.int32, name = 'Iterations')
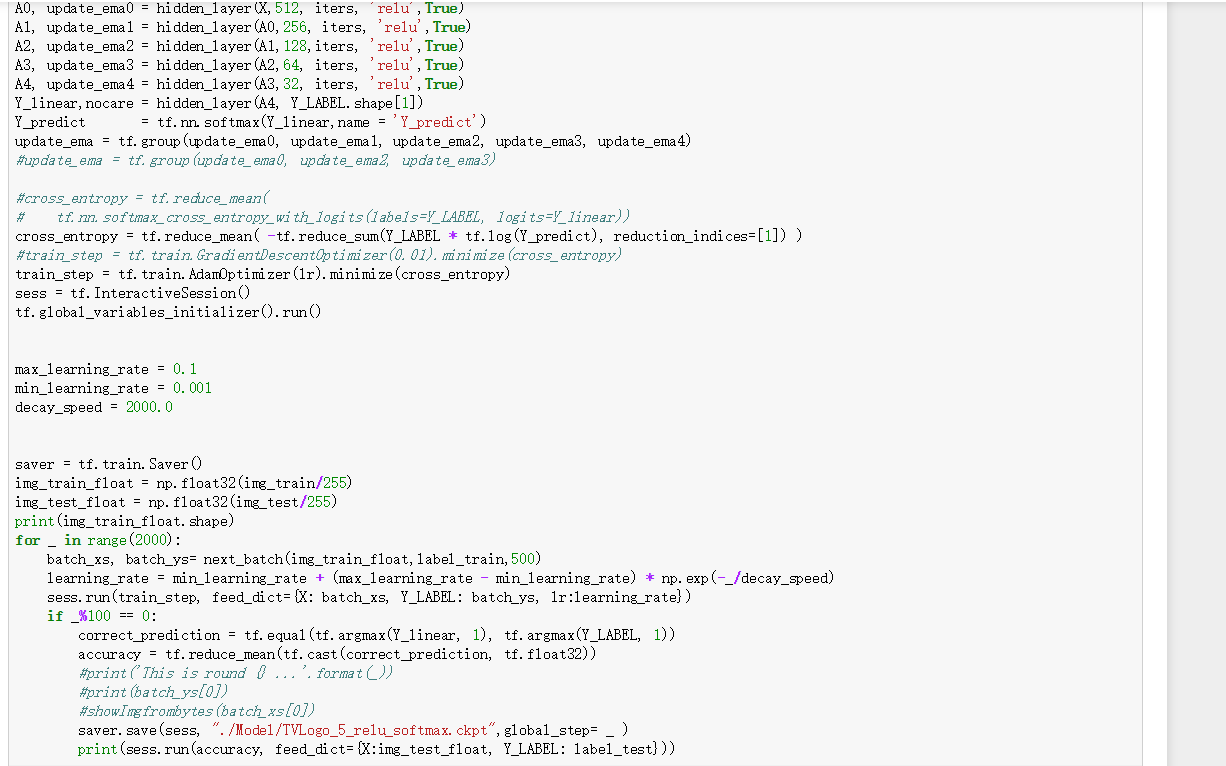
A0, update_ema0 = hidden_layer (X,512, iters, 'relu',True)
A1, update_ema1 = hidden_layer (A0,256, iters, 'relu',True)
A2, update_ema2 = hidden_layer (A1,128,iters, 'relu',True)
A3, update_ema3 = hidden_layer (A2,64, iters, 'relu',True)
A4, update_ema4 = hidden_layer (A3,32, iters, 'relu',True)
Y_linear,nocare = hidden_layer (A4, Y_LABEL.shape [1])
Y_predict = tf.nn.softmax (Y_linear,name = 'Y_predict')
update_ema = tf.group (update_ema0, update_ema1, update_ema2, update_ema3, update_ema4)
#update_ema = tf.group (update_ema0, update_ema2, update_ema3)
#cross_entropy = tf.reduce_mean (
# tf.nn.softmax_cross_entropy_with_logits (labels=Y_LABEL, logits=Y_linear))
cross_entropy = tf.reduce_mean ( -tf.reduce_sum (Y_LABEL * tf.log (Y_predict), reduction_indices=[1]) )
#train_step = tf.train.GradientDescentOptimizer (0.01).minimize (cross_entropy)
train_step = tf.train.AdamOptimizer (lr).minimize (cross_entropy)
sess = tf.InteractiveSession ()
tf.global_variables_initializer ().run ()
max_learning_rate = 0.1
min_learning_rate = 0.001
decay_speed = 2000.0
saver = tf.train.Saver ()
img_train_float = np.float32 (mnist.train.images)
img_test_float = np.float32 (mnist.test.images)
print (img_train_float.shape)
for _ in range (2000):
#batch_xs, batch_ys= next_batch (img_train_float,label_train,500)
batch_xs, batch_ys= batch_xs, batch_ys = mnist.train.next_batch (500)
learning_rate = min_learning_rate + (max_learning_rate - min_learning_rate) * np.exp (-_/decay_speed)
sess.run (train_step, feed_dict={X: batch_xs, Y_LABEL: batch_ys, lr:learning_rate})
if _%100 == 0:
correct_prediction = tf.equal (tf.argmax (Y_linear, 1), tf.argmax (Y_LABEL, 1))
accuracy = tf.reduce_mean (tf.cast (correct_prediction, tf.float32))
#print ('This is round {} ...'.format (_))
#print (batch_ys [0])
#showImgfrombytes (batch_xs [0])
saver.save (sess, "./Model_Minst/TVLogo_5_relu_softmax.ckpt",global_step= _ )
#print (sess.run (accuracy, feed_dict={X:img_test_float, Y_LABEL: label_test}))
print (sess.run (accuracy, feed_dict={X:img_test_float, Y_LABEL: mnist.test.labels}))
2.保存成 pb 文件
import tensorflow as tf
with tf.Session () as sess:
# 初始化变量
sess.run (tf.global_variables_initializer ())
# 获取最新的 checkpoint,其实就是解析了 checkpoint 文件
latest_ckpt = tf.train.latest_checkpoint ("./Model_Minst")
# 加载图
restore_saver = tf.train.import_meta_graph ('./Model_Minst/TVLogo_5_relu_softmax.ckpt-1900.meta')
# 恢复图,即将 weights 等参数加入图对应位置中
restore_saver.restore (sess, latest_ckpt)
# 将图中的变量转为常量
output_graph_def = tf.graph_util.convert_variables_to_constants (
sess, sess.graph_def , ["Y_predict"])
# 将新的图保存到"/pretrained/graph.pb"文件中
tf.train.write_graph (output_graph_def, 'pretrained', "graph_minst.pb", as_text=False)
3.调用 2 中生成的 pb 文件预测数据
def recognize (img_input, pb_file_path):
with tf.Graph ().as_default ():
output_graph_def = tf.GraphDef ()
with open (pb_file_path, "rb") as f:
output_graph_def.ParseFromString (f.read ())
_ = tf.import_graph_def (output_graph_def, name="")
with tf.Session () as sess:
#init = tf.global_variables_initializer ()
#sess.run (init)
input_x = sess.graph.get_tensor_by_name ('Input:0')
#print (input_x)
out_softmax = sess.graph.get_tensor_by_name ("Y_predict:0")
# print out_softmax
# out_label = sess.graph.get_tensor_by_name ("output:0")
# print out_label
# img = io.imread (jpg_path)
# img = transform.resize (img, (224, 224, 3))
img_try = img_input
test_input = np.float32 (img_try/255)
img_out_softmax = sess.run (out_softmax, feed_dict={input_x:test_input})
#print ("img_out_softmax:",img_out_softmax)
prediction_labels = np.argmax (img_out_softmax, axis=1)
#print ("label:",prediction_labels)
return prediction_labels
start = 30
for i in range (1,30):
r = recognize (mnist.test.images [start:start+i], "./pretrained/graph_minst.pb")
print (r)
结果:
TV Logo Recog_5relusoftmax_reducing_lr -Debug On Minst.rar (1.9 KB)
oceancjc(提问者),发表于 2018-5-8 22:33:40