文 / Pankaj Kanwar、Peter Brandt 和 Zongwei Zhou,TensorFlow 团队
衡量机器学习性能的业界标准 MLPerf (发布了 MLPerf Training v0.7 轮的最新基准测试结果。我们开心地与大家分享,Google 的提交结果展现出一流的性能(达到目标质量用时最短),能够扩展至 4,000 多个加速器,并且在 Google Cloud 上为 TensorFlow 2 开发者提供了灵活的开发体验。

在本文中,我们将探讨 TensorFlow 2 MLPerf 提交结果,以及这些结果展示了企业如何在 Google Cloud 中尖端的 ML 加速器上运行 MLPerf 所代表的有价值的工作任务,如广泛部署的几代 GPU 和 Cloud TPU(您可参考这篇 文章 中重点介绍的创纪录的大规模训练结果)。
TensorFlow 2:专为性能和易用性而设计
在今年早些时候举行的 TensorFlow 开发者峰会上,我们着重介绍了 TensorFlow 2 将注重易用性和实际性能。为争取赢得基准测试,工程师们往往依赖于低阶 API 调用和硬件专用的代码,而这些在日常企业环境中可能很少见或不实用。借助 TensorFlow 2,我们的目标是通过更直接的代码提供开箱即用的高性能,避免低级优化在代码重用性、代码运行状况和工程效率方面带来的重大问题。
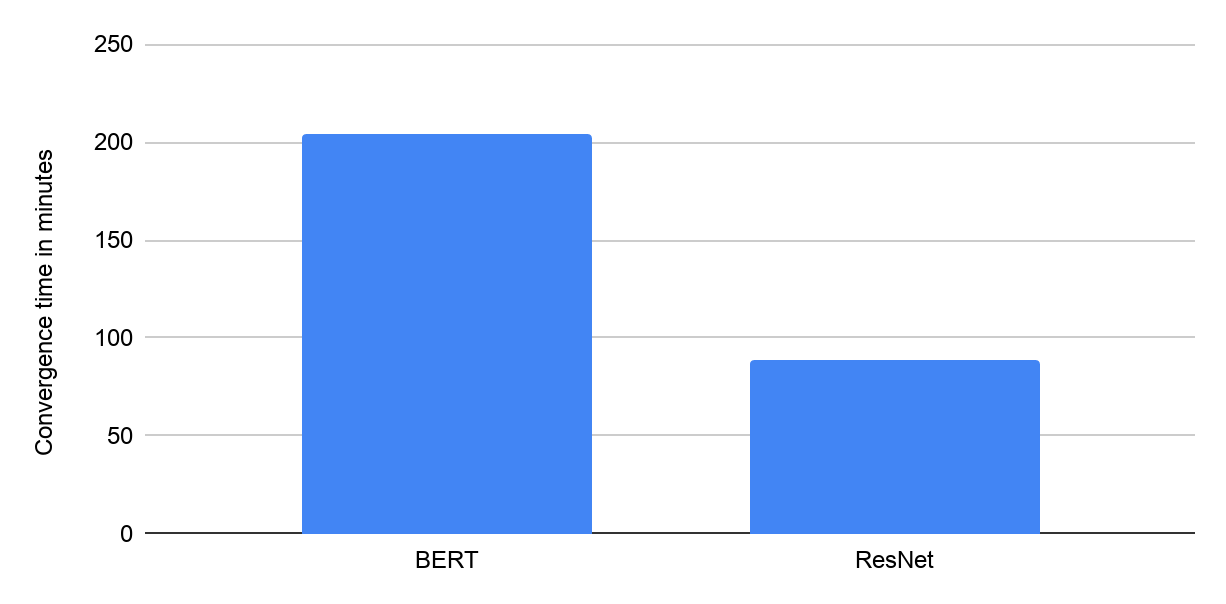
MLPerf Training v0.7 中 Google 使用带 8 个 NVIDIA V100 GPU 的 Google Cloud VM 的收敛时间(分钟)。提交结果在 “可用” 类别中。
TensorFlow 的 Keras API(请参阅相关的一系列 指南 )支持多种硬件架构,提供了易用性和可移植性。例如,模型开发者可以使用 Keras 混合精度 API 和 Distribution Strategy AP I 来使同一代码库尽可能在多个硬件平台上流畅运行。Google 的 “云端可用” 类别中的 MLPerf 提交结果是由这些 API 实现的。这些提交结果证明了使用高阶 Keras API 编写的几乎相同的 TensorFlow 代码可以在业界两个领先的广泛可用的 ML 加速器平台上提供高性能使用体验:NVIDIA 的 V100 GPU 和 Google 的 Cloud TPU v3 Pod。
注:图表中显示的所有结果均于2020年7月29日从 www.mlperf.org 中获取。MLPerf 名称和徽标为商标。有关详细信息,请访问 www.mlperf.org。显示的结果:0.7-1 和 0.7-2。
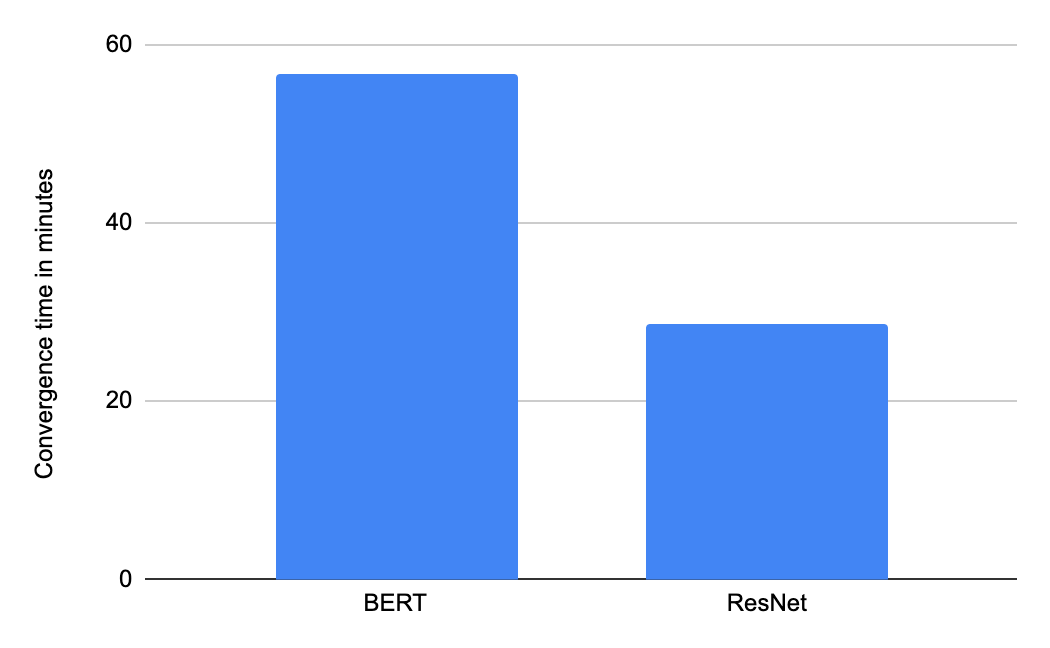
MLPerf Training v0.7 中使用含 16 个 TPU 芯片的 Google Cloud TPU v3 Pod 切片的收敛时间(分钟)。提交结果在 “可用” 类别中。
深入了解:借助 XLA 提升性能
Google 提交的在 GPU 和 Cloud TPU Pod 上的测试结果使用了 XLA 编译器 来优化 TensorFlow 性能。XLA 是 TPU 编译器技术栈的核心部分,可以选择性地为 GPU 启用。XLA 是一个基于图模型的即时编译器,用于执行各种不同类型的全程序优化,包括 ML 运算的广泛融合 。
算子融合降低了 ML 模型对存储容量和带宽的要求。此外,融合减少了运算的启动开销,尤其是在 GPU 上。总体而言,XLA 优化具有通用性和可移植性,与 cuDNN 和 cuBLAS 库的互操作性十分出色,并且通常可以作为手动编写低级内核的有力替代方案。
Google 的 “云端可用” 类别中的 TensorFlow 2 提交结果使用了 TensorFlow 2.0 中引入的 @tf.function API。@tf.function API 提供了一种简单的方法来有选择地 启用 XLA,从而可以精确控制将要编译的函数。
XLA 带来的性能提升令人赞叹:在连接 8 个 Volta V100 GPU(每个具有 16 GB GPU 内存)的 Google Cloud VM 上,XLA 将 BERT 训练吞吐量从每秒 23.1 个序列提高到每秒 168 个序列,提升了约 7 倍。XLA 还使每个 GPU 的可运行批次大小增加了 5 倍。XLA 减少了内存使用量,因此使得高级训练技术(如梯度积累)的使用成为可能。
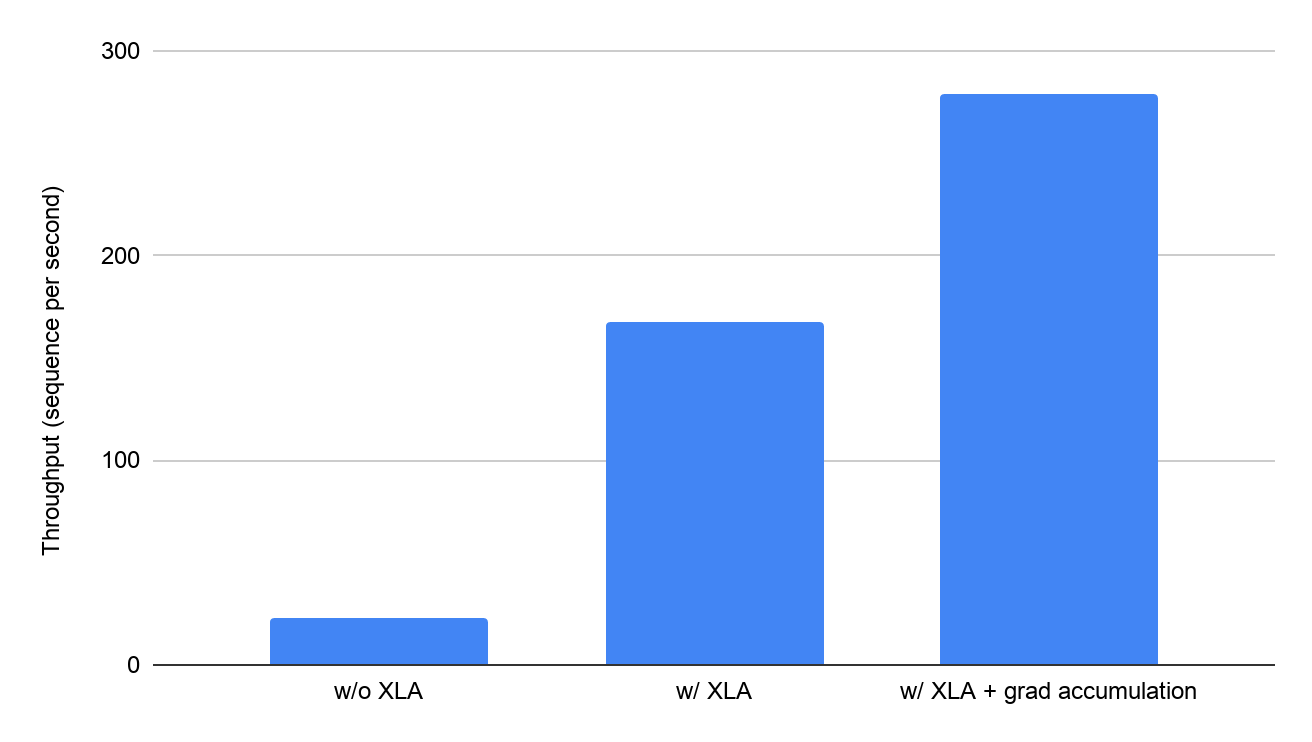
在 Google Cloud 上使用 8 个 V100 GPU 的 BERT 模型中启用 XLA 的影响(分钟)(Google 在 MLPerf Training 0.7 中提交的测试结果)与停用优化条件下同一系统中未经验证的 MLPerf 结果。
Google Cloud 上最先进的加速器
Google Cloud 是唯一支持访问最新 GPU 和 Cloud TPU 的公共云平台,使 AI 研究人员和数据科学家可以自由地为每个任务选择合适的硬件。
BERT 等前沿模型已在 Google 内广泛使用,并在整个行业范围内用于各种自然语言处理任务,现在可以使用训练 Google 内部工作任务所用的基础架构在 Google Cloud 上进行训练。借助 Google Cloud,您可以在一个小时内在具有 16 个 TPU 芯片的 Cloud TPU v3 Pod 切片上将 BERT 训练 300 万个序列,总成本不到 32 美元。
结论
Google 的 MLPerf 0.7 训练提交结果展示了 TensorFlow 2 在最新的 ML 加速器硬件上的性能、易用性和可移植性。立即开始,体验 TensorFlow 2 在 Google Cloud GPU、Google Cloud TPU 和具有 Google Cloud Deep Learning VM 的 TensorFlow Enterprise 上的易用性和功能。
致谢
GPU 的 MLPerf 提交结果离不开与 NVIDIA 的密切协作。NVIDIA 的所有工程师都为提交测试结果提供了帮助,在此一并表示感谢。
![]()
英文:TensorFlow 2 MLPerf submissions demonstrate best-in-class performance on Google Cloud
中文: TensorFlow 微信公众号