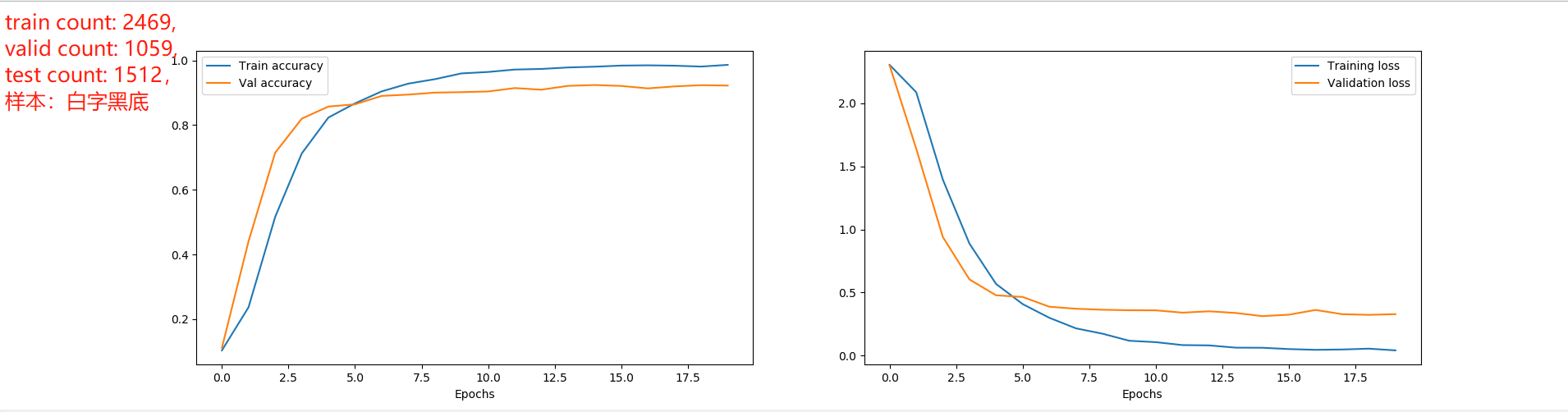
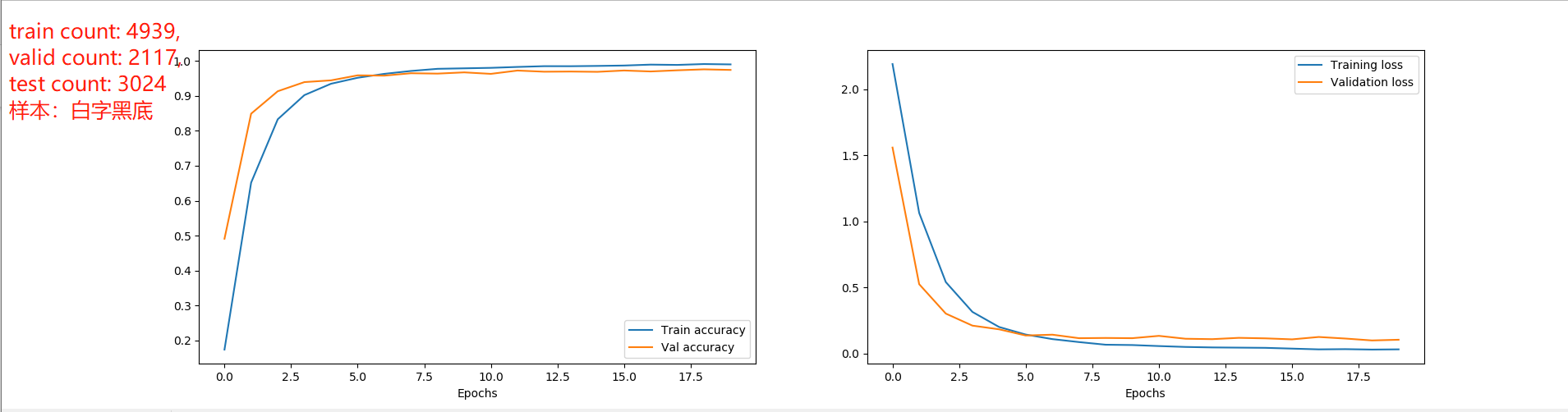
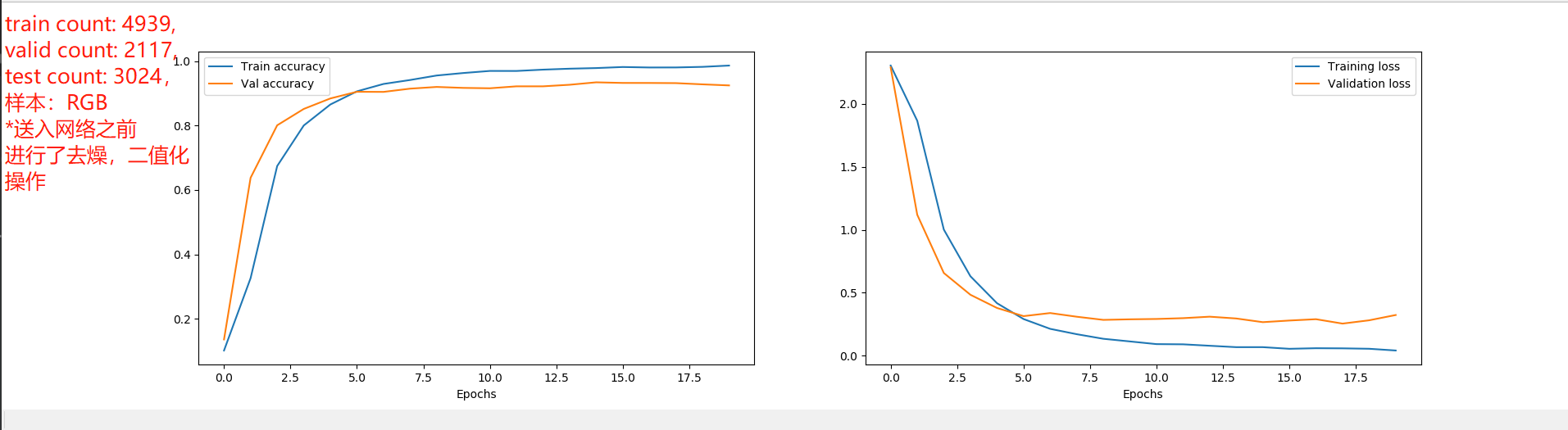
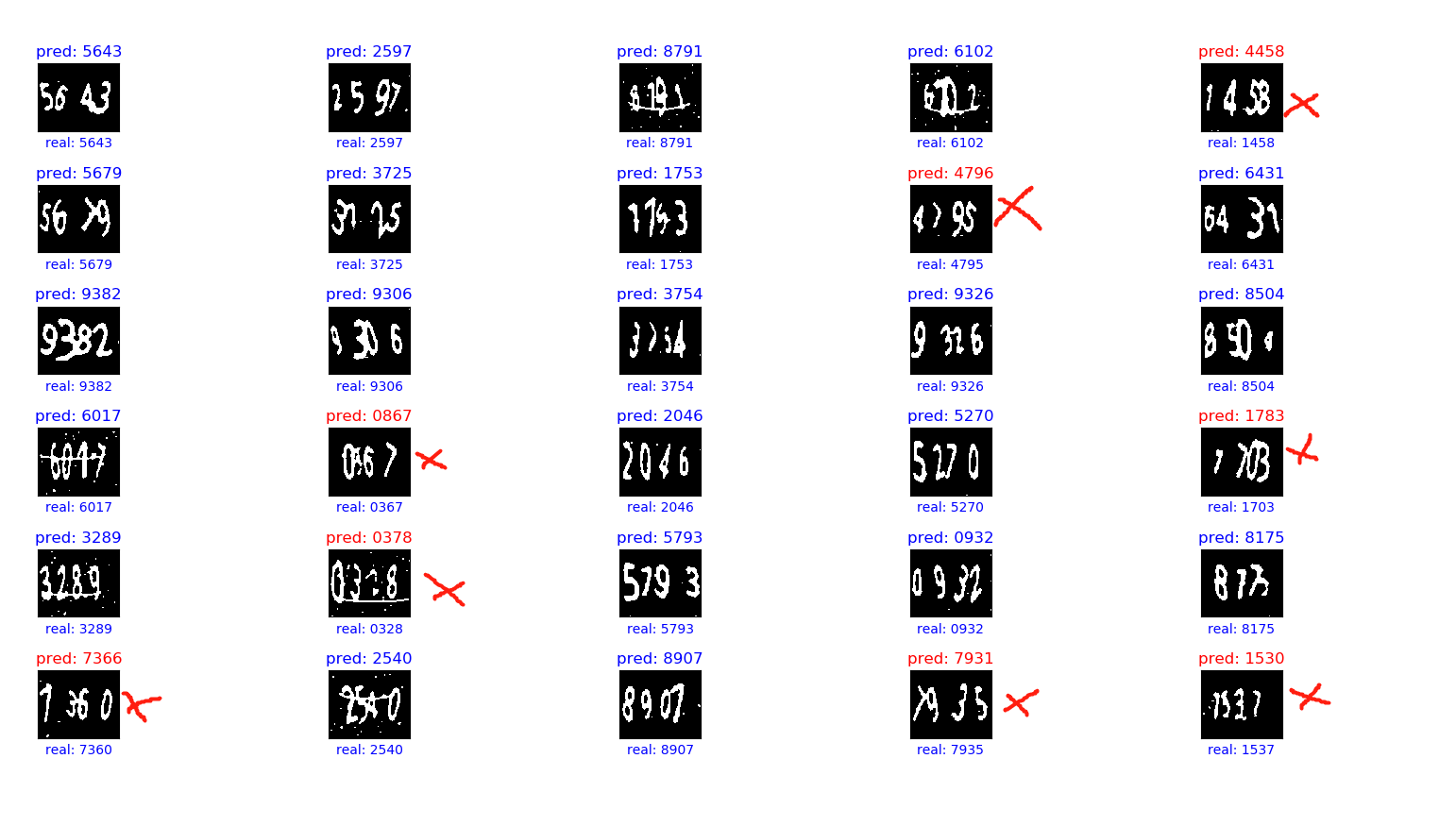
下面是我的网络模型:
model=tf.keras.models.Sequential([
tf.keras.Input(shape=(H, W, C)),
layers.Conv2D(32, 3, activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(1024, activation='relu'),
layers.Dense(D * N_LABELS, activation='softmax'),
layers.Reshape((D, N_LABELS)),
])
summary:
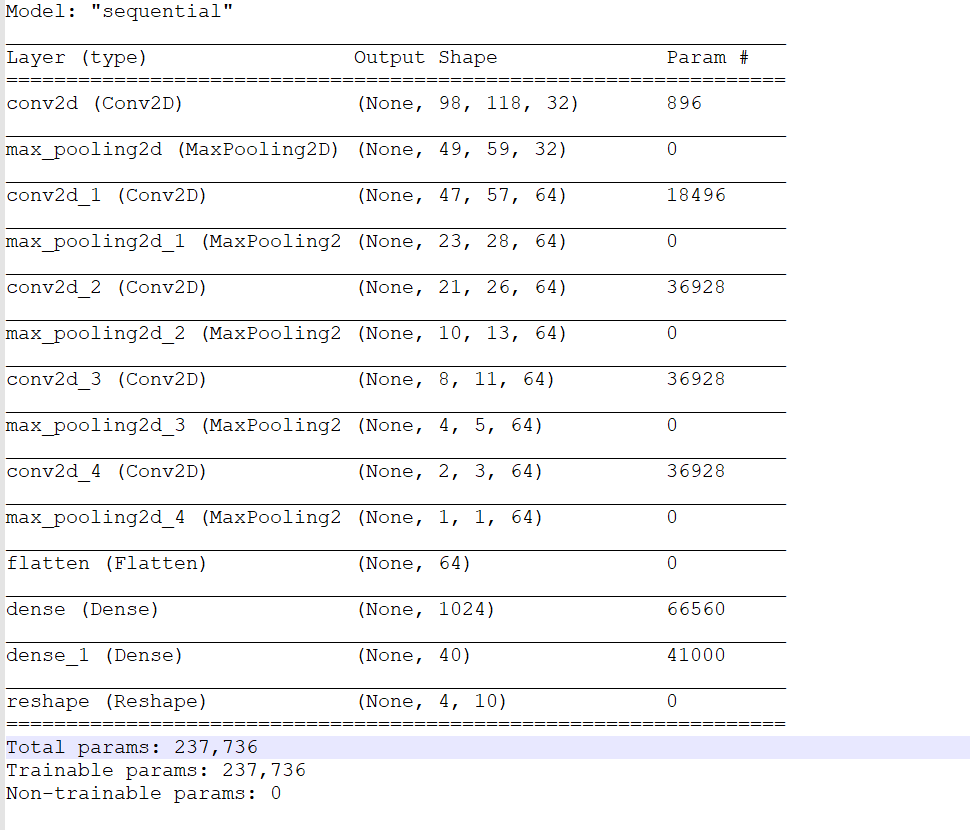
配置
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics= ['accuracy'])
callbacks=[
tf.keras.callbacks.TensorBoard(log_dir='logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=check_point_path,
save_weights_only=True,
save_best_only=True)
]
history = model.fit(train_gen,
steps_per_epoch=len(train_idx)//batch_size,
epochs=100,
callbacks=callbacks,
validation_data=valid_gen,
validation_steps=len(valid_idx)//valid_batch_size)
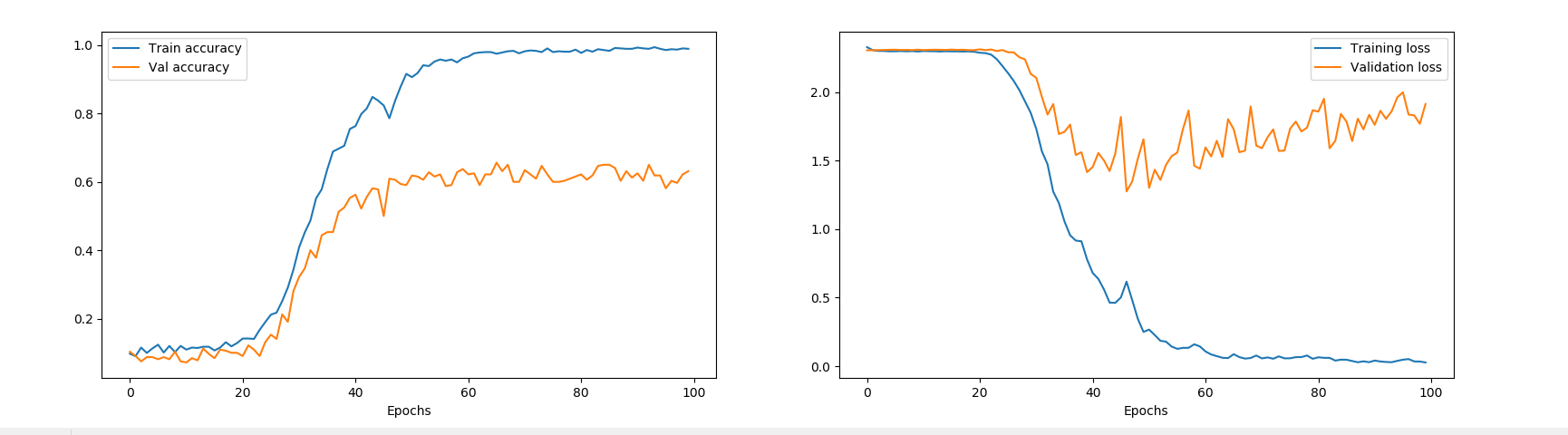
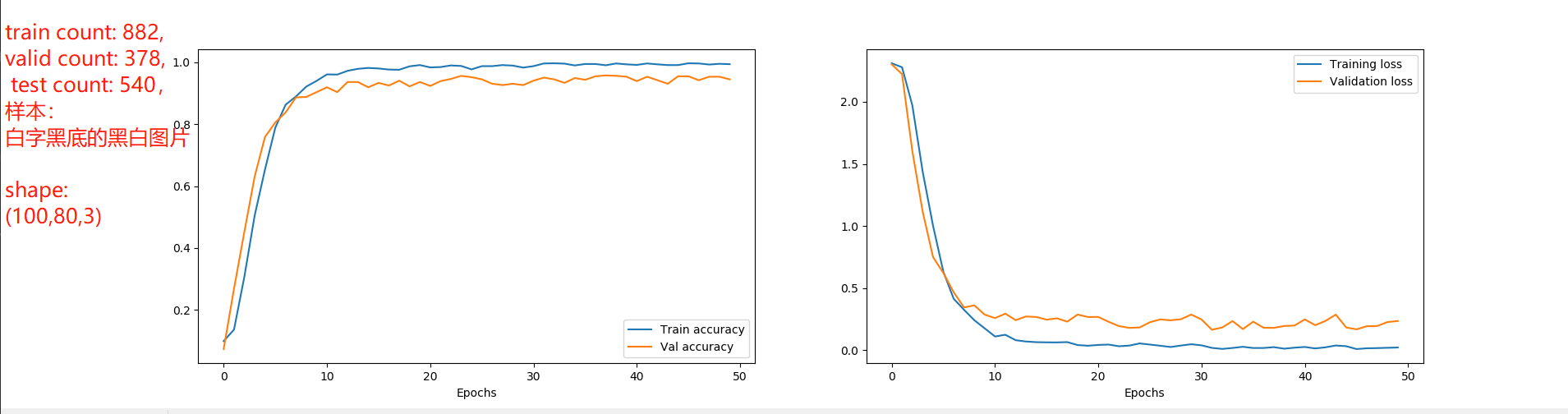
train count: 7408, valid count: 3176, test count: 4536
训练结果:
Train for 231 steps, validate for 99 steps
Epoch 1/100
1/231 […] - ETA: 4:18 - loss: 2.2984 - accuracy: 0.1328
231/231 [==============================] - 143s 618ms/step - loss: 2.3032 - accuracy: 0.0971 - val_loss: 2.3029 - val_accuracy: 0.0987
Epoch 2/100
230/231 [============================>.] - ETA: 0s - loss: 2.3026 - accuracy: 0.1014
231/231 [==============================] - 121s 525ms/step - loss: 2.3026 - accuracy: 0.1013 - val_loss: 2.3031 - val_accuracy: 0.0986
Epoch 3/100
230/231 [============================>.] - ETA: 0s - loss: 2.3026 - accuracy: 0.1029
231/231 [==============================] - 138s 597ms/step - loss: 2.3026 - accuracy: 0.1026 - val_loss: 2.3032 - val_accuracy: 0.0986
Epoch 4/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1031
231/231 [==============================] - 124s 537ms/step - loss: 2.3025 - accuracy: 0.1031 - val_loss: 2.3032 - val_accuracy: 0.0987
Epoch 5/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1040
231/231 [==============================] - 123s 532ms/step - loss: 2.3025 - accuracy: 0.1039 - val_loss: 2.3032 - val_accuracy: 0.0989
Epoch 6/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1039
231/231 [==============================] - 118s 509ms/step - loss: 2.3025 - accuracy: 0.1038 - val_loss: 2.3033 - val_accuracy: 0.0988
…
Epoch 20/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1038
231/231 [==============================] - 120s 521ms/step - loss: 2.3025 - accuracy: 0.1038 - val_loss: 2.3034 - val_accuracy: 0.0988
Epoch 21/100
190/231 [=======================>…] - ETA: 20s - loss: 2.3025 - accuracy: 0.1032
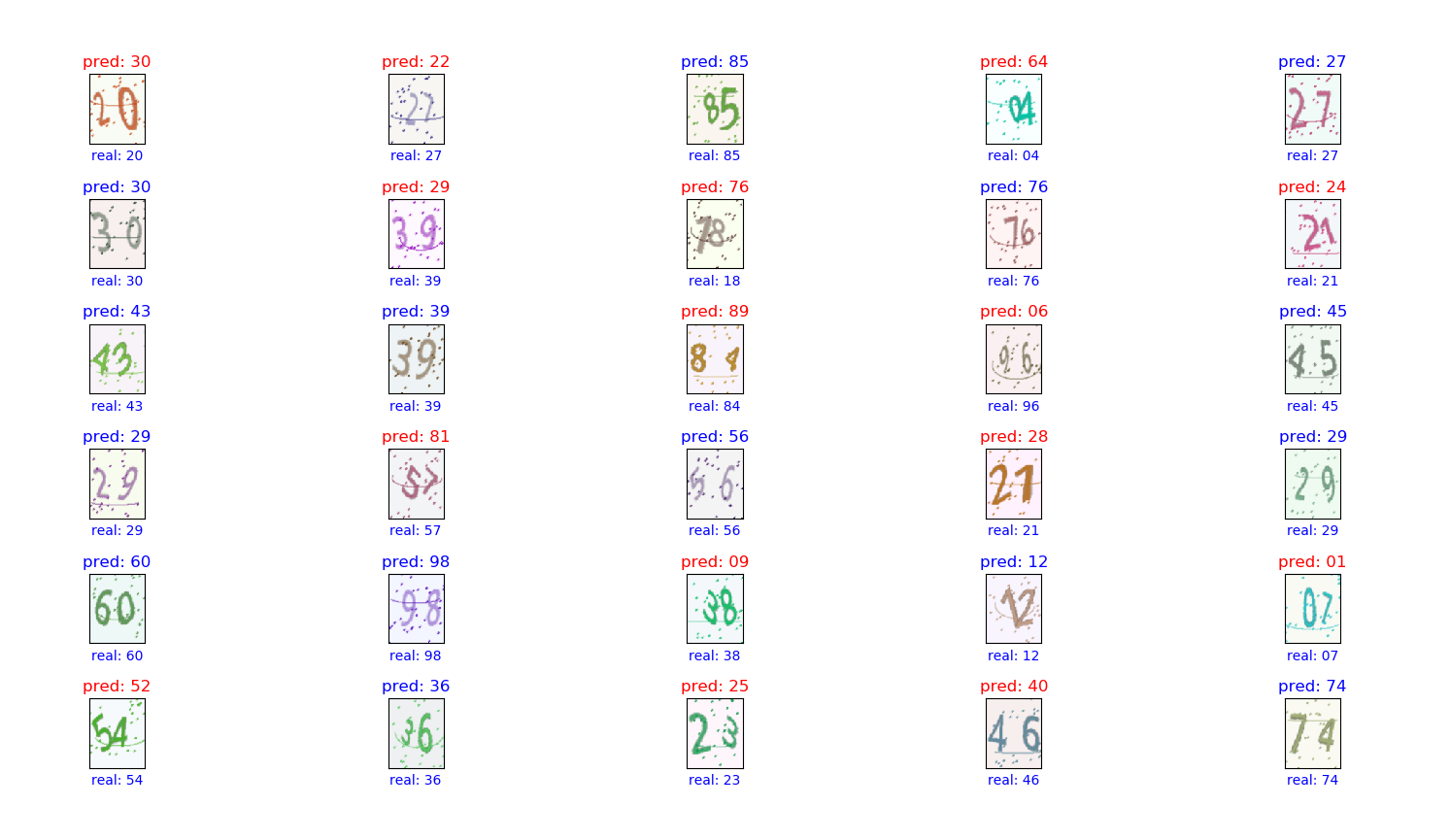
loss 一直没有变化,accuracy 也很低,请问是什么原因呢?
验证码图片是(100,120,3),是用 captcha 生成的,如图: