文/ Kevin Zakka 研究实习生和 Andy Zeng 研究员,Google 机器人团队
在我们生活的世界中,有多种形状的物体,人们会本能地去学习了解物体是如何连接的。因此,我们学会了将衣架挂在晾衣杆上,将电源插头插入墙上的插座,以及将 USB 插头插进对应的接口 。
这种基于形状“将物品组合在一起”的模式源于我们多年的生活经验,如进行 DIY 家居组装或将礼品包装好,这类经验有助于提高执行任务的效率。
如果机器人能学会这种“将物品依形状组合在一起”,那么它们在面对从未见过的事物时或许能更好地适应并完成操作任务 ,如将断裂的管道或线路重新连接好,或在灾难应急响应时利用断壁残垣搭建临时避难所。
为探究此想法的可行性,我们与斯坦福大学和哥伦比亚大学的研究员一起开发了 Form2Fit,这是一种机器人操作算法,通过深度神经网络学习识别物体彼此的对应关系(或者说“组合关系”)。
我们通过交给机器人一项组装任务来测试算法,在任务中:机器人需将多个物体正确组装到塑料包装中或摆放在货架中,形成一个整体。
在此之前,完成此类任务需要专门为任务创建一个系统,并且每次都需要大量的人工微调。但当我们从如何让机器人学习“将物品组装在一起”这个角度来尝试时,任务成功率高达 94% 。不仅如此,Form2Fit 还是首个实现泛化能力的系统,能够举一反三完成训练时未见过的新任务。

Form2Fit 通过寻找物体外观与摆放位置间的几何对应关系来学习组装。再将训练时学习到的多套件中的几何信息,泛化到新物体和新套件上
形状分析在操作中(尤其是套件组装类任务中)发挥着重要作用,虽然这经常被忽略。日常生活中 ,物体外观形状通常与包装内对应空间的形状相一致,理解这一关系后,人们在完成此类任务时可最大限度地减少无意义的猜测。
Form2Fit 的核心目的是,从多项物体和对应摆放位置的系列任务的训练中学习这种关系,以便更好地了解形状与外观如何组合。通过收集自己的训练数据,Form2Fit 不断自我完善,并最大限度地减少人工监督,在训练中反复试错,重复拆卸组装完的套件,然后颠倒拆卸顺序以提供组装步骤。
在 12 小时的训练后,机器人掌握了各种套件的高效选取和摆放策略,而且不同组合的对象和套件的组装成功率达 94%,在处理全新的物体和套件时,组装成功率超过 86%。
使用形状描述符实现泛化组装
Form2Fit 的核心是一个双流匹配网络,通过图像数据生成 可区分方向的 像素级形状描述符 (Descriptors),从而推断物体与其对应的摆放位置。这些描述符可视物体的压缩 3D 点表征,其中编码了几何形状、纹理和任务的上下文信息。Form2Fit 使用这些描述符在物体及其对应目标位置(即物体应当摆放的位置)建立对应关系。描述符可区分方向,因此 Form2Fit 在摆放物体到目标位置之前会先推断应如何旋转物体。
Form2Fit 使用另外两个网络生成 选取 和 放置 的有效候选。将物体的 3D 图像输入给选取网络,并生成选取成功率的逐像素预测。选取的成功概率显示为热力图,其中亮色表示在像素对应的 3D 位置具有更高的选取成功率。与此对应的,放置网络得到目标套件的 3D 图像,以热力图输出放置成功率的逐像素预测,其中置信度较高的像素是更适合机械臂垂直下放物体的位置。最终规划器 (Planner) 会整合这三个模块的输出,以生成最终的选取位置、摆放位置和旋转角度。
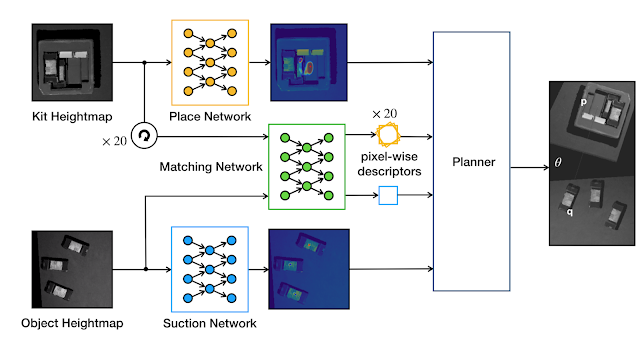
Form2Fit 概览:选取网络和放置网络可分别推断场景中的选取和摆放候选位置。匹配网络通过生成区分方向的逐像素描述符来匹配选取位置及其对应的摆放位置。规划器整合输出后控制机器人执行下一个最佳选取和摆放操作
通过拆卸学习组装
神经网络需要大量训练数据,对于组装类任务而言,很难收集足够的数据。由于随机探索的成功率很低,通过试错法很难学会以正确的方向将物体准确插入狭窄的空间中(如套件中)。
相比之下,通过试错法学习拆卸组装完的套件通常要容易一些,因为拆东西要比组装更简单。我们利用这种方法来积累 Form2Fit 的训练数据。

通过时间反转法进行自监督学习的示例:倒放除臭剂套装的拆卸顺序,生成有效的组装顺序
我们观察到的一个心得是:在多类组装套件中,反转拆卸顺序即为有效的组装顺序。这个被称为 时间反向拆卸 (Time-Reversed Disassembly) 的概念可帮助 Form2Fit 完全通过自监督进行训练,这需要通过对完整组装的套件进行反复试错随机选取的组件进行拆卸,然后反转该拆卸顺序,以学习如何将套件组装到一起。
泛化结果
我们的实验结果显示出学习组装泛化策略的巨大潜力。例如,在训练仅在一个特定位置和方向组装套件的策略时,测试时随机旋转组件或调换为相似套件,仍能保持 90% 的正确率。

Form2Fit 训练出的策略具有很好的稳定性,可适应套件的各种旋转变换和相似替换
我们还发现 Form2Fit 能够处理训练时未接触过的新组合。例如,在针对两种单一物体套件(将牙线放入盒)训练策略时,我们发现此算法可以成功组装这些套件的新组合和混合搭配,即使以前从未见过这样的组合。

Form2Fit 策略可泛化到新套件组合,比如相同套件的多种版本以及不同套件的混合组合
此外,在遇到未经训练的全新套件时,Form2Fit 还可以使用学到的形状进行归纳,然后再组装这些套件,并且组装正确率超过 86%。

Form2Fit 策略可以泛化到未曾见过的单个和多个物体套件
描述符学到什么?
为研究 Form2Fit 匹配网络的描述符如何学习与编码,我们使用了一种称为 t-SNE 的嵌入技术以 RGB 显示各种对象的逐像素描述符。

嵌入 t-SNE 的物体描述符。相同类别相似朝向的物体显示相同颜色(例如 A、B 或 F、G),而不同物体(例如 C、H)以及不同朝向的相同物体(例如A、C、D 或 H、F)则显示不同颜色
我们观察到描述符学习对以下内容编码:
- 旋转 — 朝向不同的物体使用不同的描述符(A、C、D、E)和(H、F);
- 空间对应关系 — 相同朝向物体对应的点共用相似的描述符(A、B)和(F、G);
- 物体识别 — 外形相似却是不同种类的动物和水果显示的是不同的描述符(第 3 列和第 4 列)。
目前的局限与未来工作
虽然 Form2Fit 的结果令人鼓舞,但此算法也存在一定的局限性,这将是今后研究人员工作的重点。在实验中,我们假设仅使用 2D 平面工作区以限制套件组装任务,因此仅需要上下操作进行选取和摆放便可解决问题。此策略显然并不适用于所有组装情况,例如,将钉子以 45 度角精确钉入平面。将 Form2Fit 拓展到更复杂的 3D 组装操作中将会非常有趣。
您可以了解更多相关研究成果,也可以从我们的 GitHub 主页 (https://form2fit.github.io/) 下载代码。
请点击查看视频阅读更多:原始视频,Bilibili 搬运。
致谢
这项研究由 Kevin Zakka、Andy Zeng、Johnny Lee 和 Shuran Song(哥伦比亚大学教职员)共同完成,在此特别感谢 Nick Hynes、Alex Nichol 和 Ivan Krasin 开展的卓有成效的技术讨论;Adrian Wong、Brandon Hurd、Julian Salazar 和 Sean Snyder 提供的硬件支持;Ryan Hickman 提供的妥善管理支持;以及 Chad Richards 提供的写作的建议。
原文: Learning to Assemble and to Generalize from Self-Supervised Disassembly
中文:TensorFlow 公众号