文 / 研究员 Ting Chen 和 Google Research 副总裁兼工程研究员 Geoffrey Hinton
最近的 BERT 和 T5 等自然语言处理模型表明,如果预先使用大量未标记数据集进行预训练,再使用少量的标记数据集进行微调,就可以获得良好结果。同样,根据 Exemplar-CNN、实例区分、对比预测编码、AMDIM、对比多视图编码、动量对比 等方法的相关文章所述,使用大量未标记图像数据集进行预训练有可能会提高在计算机视觉任务上的表现。这些方法属于自监督学习,自监督学习包含一系列技术,通过从未标记数据集中创建代理标签,进而将无监督学习问题转换为自监督学习问题。但是,当前用于图像数据的自监督学习技术非常复杂,需要对架构或训练程序进行大幅修改,并且尚未得到广泛应用。
在《视觉表征对比学习的简单框架》 (A Simple Framework for Contrastive Learning of Visual Representations) 中,我们阐述了一种方法,可简化并改进先前针对图像的自监督表征学习。我们提出的框架名为 SimCLR,可大幅提升自监督和半监督学习的效果 (SOTA),并能以数量有限的类别标记数据达到新的图像分类记录(使用 ImageNet 数据集中 1% 的标记图像,top-5 准确率可达 85.8%)。此方法非常简单,我们可轻松将其整合到现有的监督学习流水线中。在下文中,我们会先介绍 SimCLR 框架,然后探讨在开发 SimCLR 期间发现的三个结论。
SimCLR 框架
首先,SimCLR 使用未标记数据集, 学习 图像的通用表征,然后使用少量的标记图像进行微调,从而出色地完成给定的分类任务。SimCLR 可使用称为 对比学习 (Contrastive Learning) 的方法,将同一图像的不同转换视图间的一致性升至最高,同时将不同图像的转换视图间的一致性降至最低,从而习得 通用表征 。使用此对比目标升级神经网络参数会对应视图的表征造成互相“吸引”,而非对应视图的表征则互相“排斥”。
首先,SimCLR 从原始数据集中随机选取样本,结合几种简单增强方法(随机裁剪、随机颜色失真和高斯模糊)将每个样本转换两次,从而创建两组对应视图。对单个图像进行这些简单转换的基本原理如下:
- 我们想要实现转换后同一图像的“一致性”表征;
- 由于预训练数据缺少标签,我们无法 预知 哪个图像包含哪个对象类别;
- 我们发现尽管也可以运用更多 复杂的转换策略,但这些简单转换足以满足神经网络学习良好表征的需要。
然后,SimCLR 使用基于 ResNet 架构的卷积神经网络变量计算图像表征。之后,SimCLR 会使用全连接层网络(即多层感知器 (MLP))计算图像表征的非线性投影,进而放大不变特征,并最大化网络识别同一图像的不同转换视图的能力。我们使用随机梯度下降来更新卷积神经网络 (CNN) 和 MLP,从而最小化对比目标的损失函数。使用未标记图像进行预训练后,我们可以直接使用 CNN 的输出作为图像的表征,或者使用标记图像对 CNN 进行微调,以便其更好地完成下游任务。

SimCLR 框架的示意图:CNN 和 MLP 层同时进行训练,对于同一图像的不同增强版本可产生相似投影,而对于不同图像则产生不同的投影(即使这些图像属于同一对象类型);训练后的模型不仅能够出色识别同一图像的不同转换视图,还可以学习相似概念的表征(如椅子与狗),这一能力随后可以通过微调与标签相关联
性能
除简单之外,SimCLR 还可大幅提升自监督和半监督学习在 ImageNet 上的效果 (SOTA)。如下图所示,线性分类器会针对基于 SimCLR 学习的自监督表征进行训练,相较于先前最先进的框架 (CPC v2) 71.5% 和 90.1% 的 top-1 和 top-5 准确率,其相应可实现 76.5% 和 93.2% 的 top-1 和 top-5 准确率,性能与在较小模型 ResNet-50 中的监督学习相当。
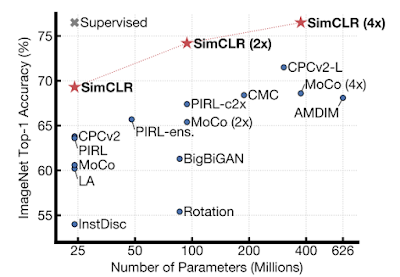
通过以不同自监督方法习得的表征训练后,线性分类器所实现的 ImageNet top-1 准确率(灰色十字表示监督 ResNet-50)
仅用 1% 的标签进行微调时,SimCLR 的 top-1 和 top-5 准确率分别可达 63.0% 和 85.8%,而先前最先进的框架 (CPC v2) 的准确率分别为 52.7% 和 77.9%。出乎意料的是,使用 100% 标签进行微调时,预训练的 SimCLR 模型仍遥遥领先于从头训练的监督基线模型。例如,微调的 SimCLR 预训练 ResNet-50 (4x) 可在 30 个周期中实现 80.1% 的 top-1 准确率,而从头训练时,此模型在 90 个周期中的准确率为 78.4%。
了解表征的对比学习
SimCLR 对先前方法的改进源于设计选择的结合,而非其中的任何单一选择。下文总结了几个重要结论。
结论 1:用于生成对应视图的图像转换组合至关重要。
SimCLR 可将同一图像的不同视图间的一致性升至最高,并以此进行表征学习,因此我们必须组合不同的图像转换以避免形式琐碎的一致性,如颜色直方图的一致性问题。为更好地了解这一点,我们探索了不同类型的转换,如下图所示。

以上样本随机选取自原始图像应用的转换
我们发现,尽管研究的单一转换均不足以定义可生成最佳表征的预测任务,但 随机裁剪 和 随机颜色失真 这两种转换结合时表现突出。尽管裁剪和颜色失真本身均无法提高性能,但两者结合却可以达到最高水准的结果。
若要了解随机裁剪和随机颜色失真相结合的重要性,那就要考虑将同一图像的两种裁剪视图间的一致性最大化的过程。此过程自然包括两种预测任务,这些任务可实现有效的表征学习:
- 在较大的全局视图(裁剪视图 B)中预测局部视图(如下图裁剪视图 A 所示);
- 预测相邻视图(如裁剪视图 C 和裁剪视图 D 之间)。
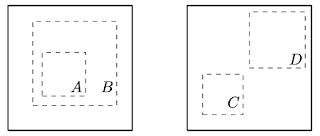
最大化不同裁剪视图间的一致性可生成两种预测任务
左侧:全局视图与局部视图;右侧:相邻视图
但是,在色彩空间方面,同一图像的不同裁剪视图通常看起来非常相似。如果颜色保持不变,模型只需匹配色值方图即可最大化裁剪视图间的一致性。在这种情况下,模型可能仅关注颜色,而忽略其他可泛化特征。单独改变每个裁剪视图的颜色可移除这些浅显的线索,此时模型仅可通过学习有用的可泛化表征来实现一致性。
结论 2:非线性投影非常重要。
在 SimCLR 中,在计算对比学习目标的损失函数之前,应用基于 MLP 的非线性投影可帮助识别每个输入图像的不变特征,并最大化网络识别同一图像的不同转换视图的能力。经我们实验发现,使用此类非线性投影有助于提高表征质量,进而将使用 SimCLR 学习的表征训练的线性分类器性能提高 10%。
有趣的是,通过对比 MLP 投影模块输入的表征和投影的输出,我们发现使用线性分类器测量时,早期表征的表现更好。由于对比目标的损失函数基于投影的输出,投影之前的表征表现更好着实出乎我们的意料。我们推测,目标会使网络的最后一层不因颜色等特征改变,而这些特征对下游任务可能有用。借助额外的非线性投影头,投影头之前的表征层可保留更多有用的图像信息。
结论 3:扩大训练规模可大幅提升性能。
我们发现:(1) 在同一批次中处理更多样本、(2) 使用更大的网络以及 (3) 训练更长时间均可显著提升性能。尽管这些观察结果显而易见,但相比于监督学习, 这些 改进 对 SimCLR 而言影响更大。例如,我们观察到,在 ImageNet 上训练时,监督 ResNet 的性能会在 90 至 300 个训练周期间达到峰值,而 SimCLR 即使经过 800 个训练周期也能继续提高性能。当我们增加网络的深度和宽度时,似乎也是这种情况:SimCLR 继续提高,而监督学习则开始饱和。我们在实验中广泛应用 Cloud TPU,以便优化扩大训练规模的回报。
代码和预训练模型
为加快自监督和半监督学习的研究进程,我们乐意与更大的学术社区分享 SimCLR 代码和预训练模型。您可在我们的 GitHub 代码库 中找到 SimCLR 代码和预训练模型。
致谢
本次成果是与 Simon Kornblith 和 Mohammad Norouzi 合作研究的。我们想要感谢 Tom Small 提供的 SimCLR 框架可视化支持。同样要感激多伦多和世界各地的 Google Research 团队提供的支持。
原文: Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
中文:TensorFlow 公众号