谢谢, 我试试
1 Like
请问多任务学习应当如何定义Loss函数,不使用keras.model.fit 。 
这就完全要看具体场景了,多任务学习的范围还是比较大的,可以参考一下相关论文里用了什么loss。
能不能举个简单例子说明,就用最简单的模型,有两个输入,两个输出,loss函数为两个binary_cross_entropy相加,权重设置为0.7,0.3,该如何实现呢?
那就按照你说的,
loss = 0.7 * tf.keras.losses.binary_crossentropy(y_true_1, y_pred_1) + \
0.3 * tf.keras.losses.binary_crossentropy(y_true_2, y_pred_2)
是这个意思吗?
1、在自定义层这一段的概括性代码使用的是add_weight,但在线性回归的示例中使用的却是add_variable。请问这两个函数有什么区别?
2、在build里面有一个量是input_shape,请问为什么不和units一起在__init__里面一起定义呢?
这是可以的,请看我发的贴子
3.1节简单的线性模型 y_pred = a * X + b代码中,损失函数计算是loss = tf.reduce_mean(tf.square(y_pred - y)),不明白这里为什么要用tf.reduce_mean,均方误差不应该是用tf.reduce_sum吗?
原文是reduce_sum呀,或许你想问的是注释4的内容,参考 https://tf.wiki/zh_hans/basic/basic.html#f2
- 没什么区别,应该一个是另一个的别名,新版统一起见推荐使用 add_weight
- build是在第一次使用该层的时候调用的,input_shape是第一次调用的时候输入的张量大小,在这里创建变量可以使得变量的形状自适应输入的形状。如果在__init__里面定义就没法根据第一次输入的数据形状来定义变量了。
1 Like
get_batch 的实现中,每次都取随机数,这样有些类似bagging,所以每个epoch应该也是有三成数据没用到。我的理解有问题吗?先shuffle再依次取batch会更好吗?
参考 TensorFlow 模型建立与训练 - #67 by snowkylin
这里只是为了实现方便。如果确实反复有读者对此表示疑问,下一版可能会改。
好的。我觉得可以文中提一下实际中一般使用的方法。
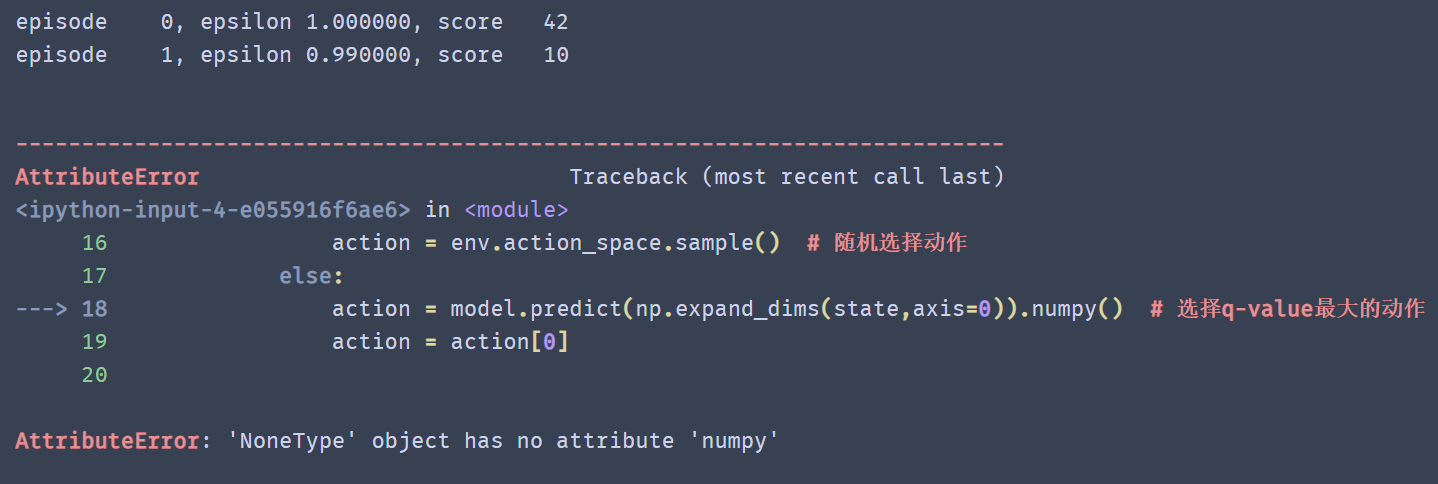
楼主好,请问
index = np.random.randint(0, self.num_train_data, batch_size)
这段代码难道不会造成产生的随机数重复出现嘛?
1 Like
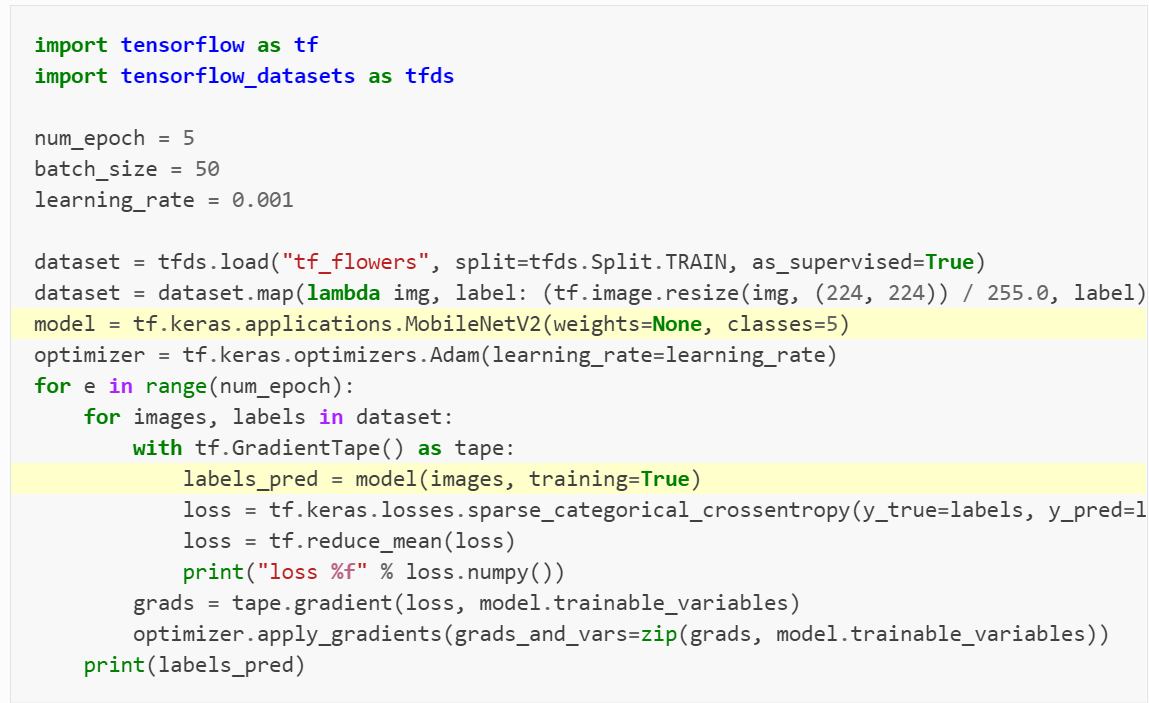
您好,在运行这段代码时,程序报错:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbe in position 141: invalid start byte
请问是什么问题。
随机数重复出现其实并没有什么关系,参考 TensorFlow 模型建立与训练 - #67 by snowkylin
“UnicodeDecodeError: ‘utf-8’ codec can’t decode byte”这种属于Python程序的问题,可能是你代码哪里出现了对中文的处理。你可以贴出你写的代码并具体指出是哪一行出了问题。
感谢,已经解决了。
1 Like
勘误:下载 MNIST 数据集 mnist.npz 文件,并放置于用户目录的 .keras/dataset 目录下
这里正确目录应该为’.keras/datasets’
谢谢作者的分享
1 Like
楼主好,有没有关于内存释放的资料,我在使用for batch_index in range(num_batachs) 训练的时候,内存一直增长,如果训练的多了,就会因内存问题报错