老师,2卡训练时,一会第一张卡利用率100%,一会另一张卡利用率100%。偶尔两张卡都有利用率的数字,但加起来几乎等于100%。看起来似乎是两张卡交替进行训练,而不是同时两张卡进行训练。这种情况正常吗?您有没有遇到类似的情况。
这个是作者自己自定义的库,如果使用pycharm的调试的话可以访问我的博客https://blog.csdn.net/chengjinpei/article/details/109559294
1 Like
猫狗分类的案例中,进程被系统 kill 了。
原本设定 shuffle 中的 buffer_size=23000 时,「filling up」那段提示在 17000 左右开始跳的,但将 buffer_size 设为 17000 后的结果如上。
设为 3000 可以运行,但测试结果为 0.5
2021-04-03 08:52:42.153932: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2021-04-03 08:52:50.236294: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcuda.so.1
2021-04-03 08:52:50.332953: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:50.333729: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GTX 1080 Ti computeCapability: 6.1
coreClock: 1.645GHz coreCount: 28 deviceMemorySize: 10.92GiB deviceMemoryBandwidth: 451.17GiB/s
2021-04-03 08:52:50.333751: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2021-04-03 08:52:51.217509: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2021-04-03 08:52:51.701322: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2021-04-03 08:52:51.782884: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2021-04-03 08:52:52.604222: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2021-04-03 08:52:52.656657: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2021-04-03 08:52:54.045588: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2021-04-03 08:52:54.045893: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:54.048422: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:54.050433: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2021-04-03 08:52:54.071548: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-04-03 08:52:54.215601: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 3696000000 Hz
2021-04-03 08:52:54.218046: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x561e0843a6e0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2021-04-03 08:52:54.218108: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2021-04-03 08:52:54.353467: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:54.354079: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x561e084a60e0 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2021-04-03 08:52:54.354091: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): GeForce GTX 1080 Ti, Compute Capability 6.1
2021-04-03 08:52:54.369854: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:54.370372: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GTX 1080 Ti computeCapability: 6.1
coreClock: 1.645GHz coreCount: 28 deviceMemorySize: 10.92GiB deviceMemoryBandwidth: 451.17GiB/s
2021-04-03 08:52:54.370390: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2021-04-03 08:52:54.370403: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2021-04-03 08:52:54.370410: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2021-04-03 08:52:54.370433: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2021-04-03 08:52:54.370441: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2021-04-03 08:52:54.370449: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2021-04-03 08:52:54.370457: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2021-04-03 08:52:54.370490: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:54.371053: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:54.371598: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2021-04-03 08:52:54.374713: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2021-04-03 08:52:58.258231: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-04-03 08:52:58.258296: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0
2021-04-03 08:52:58.258314: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N
2021-04-03 08:52:58.265982: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:58.267274: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-04-03 08:52:58.268442: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10264 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1)
Epoch 1/10
2021-04-03 08:53:00.112317: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2021-04-03 08:53:09.853207: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 2266 of 17000
2021-04-03 08:53:19.825211: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 4605 of 17000
2021-04-03 08:53:29.838732: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 7442 of 17000
2021-04-03 08:53:39.827247: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 10321 of 17000
2021-04-03 08:53:49.820449: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 13252 of 17000
2021-04-03 08:53:59.830633: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:172] Filling up shuffle buffer (this may take a while): 16307 of 17000
2021-04-03 08:54:02.082338: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:221] Shuffle buffer filled.
2021-04-03 08:54:03.194943: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
Killed可能需要看看操作系统的日志,查一下导致kill的原因,可能是某项计算资源不足(比如内存)

你好,请贴出你的程序代码
1 Like
import tensorflow as tf
import numpy as np
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
# MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[index, :], self.train_label[index]
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten() # Flatten层将除第一维(batch_size)以外的维度展平
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
@tf.function
def call(self, inputs): # [batch_size, 28, 28, 1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
num_epochs = 1
batch_size = 50
learning_rate = 0.001
log_dir = 'tensorboard'
# 训练
model = MLP()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
# 准备好writer
summary_writer = tf.summary.create_file_writer(log_dir) # 参数为记录文件所保存的目录
# 追踪
tf.summary.trace_on(graph=True, profiler=True)
# 训练
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
# 记录器记录loss
with summary_writer.as_default():
tf.summary.scalar('loss', loss, step=batch_index)
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
# 显示追踪
with summary_writer.as_default():
tf.summary.trace_export('model_trace', step=0, profiler_outdir=log_dir)
这是我的代码,麻烦老师帮我看看
WARNING:tensorflow:From D:\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\ops\summary_ops_v2.py:1259: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01.
Instructions for updating:
use `tf.profiler.experimental.stop` instead.
2021-06-09 13:38:25.124426: I tensorflow/core/profiler/internal/gpu/device_tracer.cc:223] GpuTracer has collected 0 callback api events and 0 activity events.
WARNING:tensorflow:From D:\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\ops\summary_ops_v2.py:1259: save (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01.
Instructions for updating:
`tf.python.eager.profiler` has deprecated, use `tf.profiler` instead.
WARNING:tensorflow:From D:\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\eager\profiler.py:151: maybe_create_event_file (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01.
Instructions for updating:
`tf.python.eager.profiler` has deprecated, use `tf.profiler` instead.
这是出现的警告,应该是Profile出了问题吧。
pip install -U tensorboard-plugin-profile
我试了pip也没有解决问题,麻烦老师啦!
我没有在2.1版本下使用过Profile。可能需要将TensorFlow升级到2.3及以上的版本来使用Profile功能,以及确认你在启动TensorBoard的时候指定了正确的路径(文件夹路径保持全英文)。
作者你好,我有个问题:model.evaluate的过程不会更新神经网络的参数,仅仅只是评估模型,那么按照道理来说,在valid数据集的每个batch评估过后所得的loss 和 accuracy 应该是在某一个值上下浮动,为什么还会出现loss逐渐下降, accuracy逐渐上升这样的过程呢
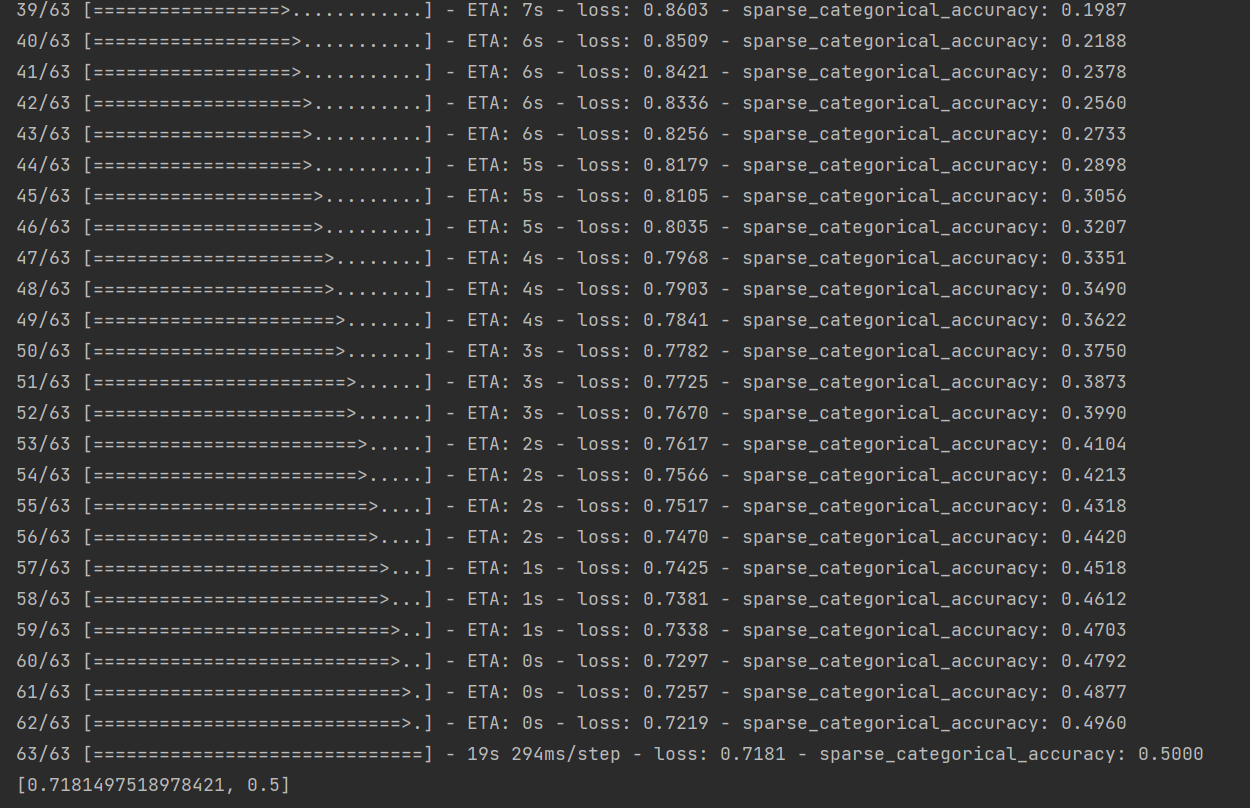
@Chenfanqing 我不知道你写了怎样的代码,但你这里展示的似乎是一个训练的过程?evaluate是不会更新参数,但训练过程会更新参数,当然是随着训练batch数的增加,loss逐渐下降, accuracy逐渐上升。如果还有疑问,可以发一下你的代码。
实例:cats_vs_dogs 图像分类
在这个实例中,总是报错
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found.
(0) Invalid argument: Trying to decode BMP format using a wrong op. Use decode_bmp or decode_image instead. Op used: DecodeJpeg
[[{{node DecodeJpeg}}]]
[[IteratorGetNext]]
[[IteratorGetNext/_2]]
(1) Invalid argument: Trying to decode BMP format using a wrong op. Use decode_bmp or decode_image instead. Op used: DecodeJpeg
[[{{node DecodeJpeg}}]]
[[IteratorGetNext]]
0 successful operations.
0 derived errors ignored. [Op:__inference_train_function_730]
Function call stack:
train_function → train_function
请问有什么方法可以跳过这些出错的照片吗
你可能需要发一下你的代码
@snowkylin 老師你好,原本提供的cats_vs_dogs連結似乎已經找不到載點了,能否提供其他方式下載該資料集呢?
不太像這個我有看,但它沒有實例中的train與valid資料夾,它只有cats與dogs兩組圖片集。
啊FloydHub居然關門了,那我把我之前下載的數據集檔案分享一下
@site 能否帮我把这个数据集文件上传到论坛服务器,这样我可以更新到文章里
2 Likes
1 Like
这里给出的profiler用法已经比较老了,profiler提供的很多功能头用不了,最新的profiler功能可以用下面这种方法:
tf.profiler.experimental.start(log_dir) #训练开始前执行
for b in range(batch):
with tf.profiler.experimental.Trace(name='自定义名字',step_num=b):
#你的训练代码
tf.profiler.experimental.stop() #训练结束后执行,保存profile数据
1 Like