文 / Marco Tagliasacchi,研究员,Google Research
音调是声音频率的定性度量,其中高音的频率高于低音的频率。通过追踪音调中的相对差异,我们的听觉系统能够识别出如歌曲的旋律等许多音频特征。由于在音乐信息检索和语音分析等诸多领域占据核心地位,基音检测已在过去几十年间引起广泛关注。
长久以来,进行基音估计的推荐方法是简单的信号处理流水线,在时域 (time domain) 进行处理(如,pYIN)或者在频域 (frequency domain) 上进行处理(例如,SWIPE)。
在此,由于缺少标注数据,机器学习无法超越上述手工设计的信号处理流水线。训练全监督模型所需的数据需要从时间分辨率和频率分辨率中获得,获取过程困难、繁琐。之后出现了 CREPE 模型,通过结合其他手动标注数据集后生成的综合数据集,CREPE 能够突破这些限制,得出最优结果 (SOTA)。
在近期发布的 论文 中,我们介绍了一种与以往不同的方法,在缺少标记数据的情况下,训练基音估计模型的方法。对人类(包括专业音乐家)而言,估计相对音高(判断两个音之间谁更高)通常会比估计绝对音高(判断出声音的实际音高,能说出音名)容易得多。受此观察结果的启发,我们设计了 SPICE(自监督式基音估计)来完成类似任务。此方法依靠 自我监督 ,方法是定义能够以完全无监督方式学习的辅助任务(Auxiliary Task,又名 Pretext Task)。

音频片段的 常数 Q 转换 (Constant-Q transform),叠加在由 SPICE 估测的音调表征上,视频
SPICE 模型包含卷积层编码器,可生成能线性映射至音高的单标量嵌入 (Single Scalar Embedding)。为实现这一点,我们编码器输入两段信号,一段是参考信号,另一段是用随机生成的向量对参考信号进行定量移调后的新信号。然后,我们设计一个损失函数,促使标量嵌入间的差异与音调间的已知定量差异成比例。为方便起见,我们按照常数 Q 变换 (CQT) 定义的域来进行音高变换,因为这相当于在对数标度的频率轴上做简单平移。
SPICE 仅会在底层信号为 谐波 (Harmonic),即一个周期中包含基频的整数倍,才会对音高作出准确定义。因此,模型的一个重要功能是确定何时可得出有意义且可靠的输出结果。例如,在下图中,由于 1.2 秒至 2 秒内没有谐波信号,所以基音估计的置信度较低,未能生成基音估计结果。SPICE 旨在以自我监督的方式来学习基音估计的置信水平,而不是依赖手工设计的解决方案。

SPICE 模型架构(简化版)。我们将同一 CQT 框架的两个音高变换版本馈送至具有共享权重的两个编码器。损失函数旨在使编码器输出间的结果差异与相对音高差异成比例。此外(未显示),另添加重构损失以对模型进行正则化调整。模型还会学习计算基音估计的置信度。
我们利用公开可用的数据集来评估我们的模型。结果表明,尽管 无法使用真实标签 ,但模型的表现优于手工设计解决方案的基线,并与 CREPE 达到的相当的准确度。此外,通过在训练期间适当地增强数据,SPICE 亦可在有噪声干扰的环境下运行,例如,当歌声与背景音乐混杂在一起时,SPICE 可提取歌声的音高。下图所示为 SWIPE(手工设计的信号处理方法)、CREPE(全监督式模型)和 SPICE(自监督式模型)在 MIR-1k 数据集上的比较结果。
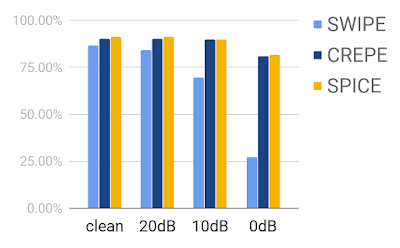
在混杂不同信噪比背景音乐的情况下,对 MIR-1k 数据集的评估结果
我们已在 FreddieMeter 中部署 SPICE 模型。FreddieMeter 是一款网络应用,演唱者可使用软件与为他们模仿 Freddie Mercury 的表现打分。
致谢
文中所述论文由 Beat Gfeller、Christian Frank、Dominik Roblek、Matt Sharifi、Marco Tagliasacchi 和 Mihajlo Velimirović 创作。
我们非常感谢 Google 的同事们对这项工作的所有探讨和反馈。本研究中用于训练模型的 SingingVoices 数据集由 Alexandra Gherghina 收集,并会成为 FreddieMeter 的一部分,该应用会使用 SPICE 和音色相似度模型来了解歌手与 Freddie Mercury 之间的相似程度。
原文:SPICE: Self-Supervised Pitch Estimation
译:TensorFlow 公众号