文 / DeepMind 研究员 Daniel J. Mankowitz 和 Google Research 研究员 Gabriel Dulac-Arnold
实践证明,强化学习 (Reinforcement Learning, RL) 可以有效应对从 AlphaGo、 AlphaStar StarCraft 和 Minecraft 到 机器人运动 与 芯片设计 的众多复杂问题。在这些情况下,人们可以使用仿真器或者通过快速访问低成本的真实环境部署强化学习 。然而,在现实世界的产品和系统中部署 RL 到仍然面临着巨大挑战。举个例子,在物理控制系统里,如机器人系统和自动驾驶系统,RL 控制器通常被训练来解决类似物体抓取或者高速路行驶的任务。这些控制器容易受到传感器噪声、系统延迟或正常磨损等影响,从而降低控制器输入的质量,导致错误的决策和引起灾难性潜在的故障。

物理控制系统:在 Google X 的 Everyday Robot Project 中,机器人正在学习如何使用 RL 抓取和挑选物体。这些类型的系统会受此处详述的现实世界挑战的影响
在“现实世界中强化学习的挑战 (Challenges of Real-World Reinforcement Learning )”一文中,我们讨论了阻碍当前 RL 算法在应用系统中应用的九种不同挑战。我们基于实证研究跟进这项工作,在最先进 (SOTA) RL 算法上模拟这几种挑战,并对各种效果进行基准测试。我们已在 现实世界的强化学习 (Real-World Reinforcement Learning,RWRL) 任务套件中开源了这些模拟挑战,旨在吸引人们关注这些重要问题,加快帮助这些问题的研究解决。
RWRL 套件
RWRL 套件是一系列受应用强化学习挑战启发的模拟任务,目标是使研究员和从业者能够快速进行算法迭代,而不必在真实系统上运行缓慢且昂贵的实验。虽然从模拟训练的 RL 算法过渡到现实世界的应用将面临其他挑战,但该套件旨在弥补一些更基本的算法差距。RWRL 目前支持 DeepMind Control Suite 域的一个子集,但套件范围将继续扩大,支持更多样化的域集。
易用且灵活
我们在设计套件时考虑了两个主要目标:
- 易用性 - 用户只需更改几行代码就能在下载套件后的几分钟内开始运行实验。
- 灵活性 - 用户应该能够将各种挑战轻松组合到环境中。
延迟动作示例
为了说明 RWRL 套件的易用性,设想一位研究员或从业者想实现动作延迟(即,动作发送到环境的时间延迟)。要使用 RWRL 套件,只需导入 rwrl 模块。接下来,使用 delay_spec 参数加载环境(例如 Cartpole)。这一可选参数被指定为字典,配置了应用于动作、观测值或奖励的延迟,以及相应元素被延迟的时间步骤数(例如 20 个时间步骤)。加载环境后,动作的效果会自动延迟,而无需对实验进行任何其他更改。因此,在 RWRL 套件支持的一系列不同环境中,很容易测试带有动作延迟的 RL 算法。

RWRL 套件的高级概述。通过几行代码就可以向环境中添加一个挑战(如动作延迟),运行超参数扫描,并生成右侧所示图形
用户只需向加载函数添加额外参数,即可组合不同挑战或从一组预定义基准挑战中选择,所有参数均在 开源的 RWRL 套件代码库 中指定。
已支持的挑战
RWRL 套件提供的功能可以支持与九种不同挑战中的八种挑战相关的实验,这些挑战使当前 RL 算法难以应用于应用系统:样本效率;系统延迟;高维状态和动作空间;约束;部分可观测性、随机性和非平稳性;多目标;实时推理;以及从离线日志训练。由于可解释性的任务抽象且难以定义,RWRL 排除了这一挑战。支持的实验并非完全详尽,让研究员和从业者能够针对各个挑战维度分析其代理的能力。支持的挑战的示例包括:
-
系统延迟
大多数真实系统在感知、激励或奖励反馈上都有延迟,这些都可以配置并应用于 RWRL 套件中的任何任务。下图显示了在动作(左)、观测值(中间)和奖励(右)越来越延迟的情况下 D4PG 代理的性能。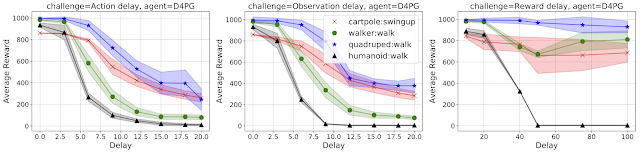
在四个 MuJoCo 域中,分别增加动作(左)、观测值(中)和奖励(右)延迟对最先进 (SOTA) RL 代理的影响。
如图所示,研究员或从业者可以迅速了解哪种类型的延迟会影响其代理的性能。这些延迟的效果也可以组合观察。
-
约束
几乎所有应用系统都在总体目标中嵌入了某种形式的约束,这在大多数 RL 环境中并不常见。RWRL 套件为每个任务实施了一系列不同难度的约束,以促进约束 RL 的研究。以下视频直观显示了违反复杂局部角速度约束的示例。
倒立摆约束违反示例。红色界面表示违反了局部角速度
-
非平稳性
用户可以通过扰动环境参数引入非平稳性。这些扰动与最近在监督式深度学习研究中越发常见的像素级对抗性扰动相反。例如,在人类步行者域,可以在整个训练过程中修改头部的大小和地面的摩擦,模拟条件变化。RWRL 套件中提供了多种调度器(请参见我们 代码库的代码 了解更多详细信息)以及多种默认参数扰动。这些扰动通过精细定义,能够限制最先进学习算法的学习能力。
非平稳扰动。该套件支持在不同片段中扰动环境参数,如更改头部尺寸(中)和接触摩擦(右)
-
从离线日志数据进行训练
在大多数应用系统中,运行实验既缓慢又昂贵。通常可以使用先前实验的数据日志来训练策略。然而,由于数据有限、方差低或质量差,往往很难在生产中胜过先前的模型。为了解决这个问题,我们生成了组合 RWRL 基准挑战的 离线数据集,并将其作为更广泛的离线数据发布的一部分。更多信息参见 此笔记本。


结论
大多数系统很少仅表现出单一挑战,因此,我们很高兴能看到算法如何应对存在多个挑战且难度不断增加(“简单”、“中等”和“困难”)的环境。我们热切希望研究社区尝试并解决这些挑战,我们相信解决这些挑战将促进 RL 在产品和现实世界系统中的更广泛的应用。
虽然 RWRL 套件最初的一系列功能和实验为缩小 RL 现状与应用系统挑战之间的差距提供了起点,但仍有许多工作尚未完成。已支持的实验并不详尽,我们欢迎广大社区提出新的想法,更好地评估 RL 代理的能力。此套件的主要目标是强调和鼓励对限制 RL 算法在应用产品和系统中有效性的核心问题开展研究,并加快未来 RL 应用的实现。
致谢
感谢我们的核心贡献者与联合作者 Nir Levine 的宝贵帮助。我们还要感谢我们的联合作者 Jerry Li、Sven Gowal、Todd Hester 和 Cosmin Paduraru,以及 Robert Dadashi、ACME 团队、Dan A. Calian、Juliet Rothenberg 和 Timothy Mann 所做的贡献。
![]()
原文: A Simulation Suite for Tackling Applied Reinforcement Learning Challenges
中文:TensorFlow 公众号