文 / 高级软件工程师 Anna Goldie 和高级研究员 Azalia Mirhoseini,Google Research 和 Google Brain 团队
计算机系统和硬件的显著进步在很大程度上推动了现代计算革命。随着 摩尔定律 和 Dennard 缩放比例定律 的放缓,旨在满足呈指数增长的计算需求的专用硬件已成为时下全球的发展方向。
然而,当今的芯片设计往往需要花费数年的时间,与此同时,我们也必须对下一代芯片发展方向进行思考:怎样才能满足自现在起 2 到 5 年内机器学习 (ML) 模型的需求。大幅缩短芯片的设计周期将有助于硬件的快速迭代,以适应发展迅速的 ML 领域。我们不禁设想:如果 ML 自身能够提供缩短芯片设计周期的方法,制造集成度更高的硬件和 ML,让两者之间能相互促进,那么情况又会如何?
在《利用深度强化学习完成芯片布局》(Chip Placement with Deep Reinforcement Learning) 一文中,我们将芯片布局定位为一个强化学习 (RL) 问题,从而通过训练智能体(即 RL 策略)来优化芯片布局。与以往相比,我们的方法具备学习过往经验并随时间推移不断改进的能力。具体来说,随着我们训练的芯片 block 越来越多,我们的方法也更擅长为之前未曾见过的芯片 block 快速生成优化布局。现有的基准方法需要专家们的参与,并且往往需要数周的时间才能完成,而我们的方法在六小时内就能生成优于或媲美人类专家设计的布局。我们已经验证它可以为 Google 加速器芯片 (TPU) 生成优化布局,但这种的方法也适用于任何类型的芯片 (ASIC)。
芯片的布局规划
计算机芯片通常分为数十个 block,每个 block 都是一个单独的模块,例如,内存子系统、计算单元或控制逻辑系统。这些 block 可以通过 网表,以及 宏 (Macro,内存组件)和 标准单元 (NAND、NOR 和 XOR 等逻辑门)等电路组件图来描述,而所有这些组件均通过导线连接。确定芯片 block 布局的过程通常称为芯片的布局规划,是芯片设计过程中最复杂,也是耗时最久的阶段之一,涉及到将网表放置在芯片的画布(2D 网格)上,以便尽量使功率、性能和面积 (PPA) 最小化,同时遵守密度和布线拥塞方面的限制。
尽管在该方向上的研究已有数十年之久,但是专家们仍然需要数周的迭代时间才能完成一个满足多方面设计标准的解决方案。
这个问题的复杂性主要来自几个方面:网表图的大小(数百万至数十亿个节点)、必须满足网表图放置要求的网格粒度,以及计算真实目标指标所产生的过高成本,即使用行业标准的电子设计自动化工具可能要花费数小时的时间(有时甚至超过一天)。
深度强化学习模型
我们模型的输入包括芯片网表(节点类型和图邻接信息)、要放置的当前节点 ID,以及一些网表元数据,比如导线、宏和标准单元集群的总数等。网表图和当前节点通过我们开发的基于边缘的 图神经网络传输,从而编码输入状态。这样能够为已部分放置的图和候选节点生成嵌入。
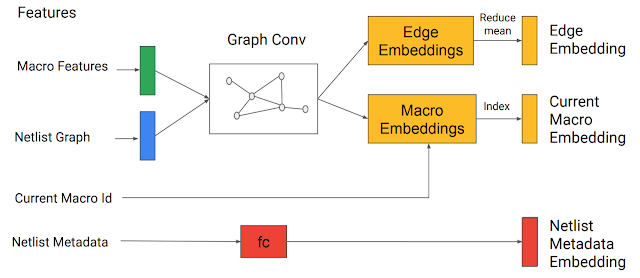
图神经网络生成的嵌入与元数据嵌入串联在一起,形成对策略网络和价值网络的输入
边缘、宏和网表元数据嵌入随后也进行串联,以形成单个状态嵌入,继而传递到 前馈神经网络。前馈网络输出一种习得表征,用于捕获有用的特征并将其用作策略网络和价值网络的输入。随后,策略网络对可以在其上放置当前节点的所有可能网格单元生成概率分布。
在每次训练迭代中,RL 智能体按顺序放置完宏,然后通过 力引导
(cellplacement.pdf) 方法放置标准单元集群,此方法将电路建模为弹簧系统,以便尽量缩短线长。RL 训练由一个快速但近似的奖励信号指导,该信号专为智能体的每个芯片布局计算,采用近似线长(即半周线长,HPWL)和近似拥塞(已放置网表消耗的布线资源比例)的加权平均值得出结果。

在每次训练迭代过程中,按策略一次放置一个宏,而标准单元集群则通过力引导方法放置。奖励根据近似线长和拥塞的加权组合计算得出
结果
据我们所知,这种方法是首个具有泛化能力的芯片布局方法,这意味着此方法可以利用习得的知识,在布局之前网表的同时,为未见过的全新网表生成更好的布局。我们发现,随着我们增加进行预训练的芯片网表数量(即,此方法在布局优化方面更有经验),我们的策略将更好地泛化至新网表。
例如,预训练策略有机地确定了一种布局:将宏放置在芯片的边缘附近,将标准单元放置在芯片中心的凸起空间。这将使宏和标准单元之间的线长变短,不会造成布线过度拥塞。相比之下,从头开始训练的策略则从随机布局开始,需要更长的时间才能收敛得到高质量的解决方案,然后重新发现了在芯片画布的中心留出一个空位的需要。具体请参阅以下动画。

开源 RISC-V 处理器 Ariane 的宏布局随训练进程的变化情况。在左图中,从头开始训练策略,而在右图中,预训练的策略已针对芯片进行了微调。每个矩形标识一个单独的宏布局。请注意,从头开始训练的策略发现的空洞一开始便存在于预训练策略的布局中
我们观察到预训练提升了样本效率和布局质量。我们将使用预训练策略生成的芯片布局质量与从头开始训练的策略所得到的布局质量进行了对比。为了给之前未见过的芯片 block 生成芯片布局,我们使用了 零次 方法,即只使用预训练策略(不进行微调)来放置新 block,并在不到一秒的时间内完成了布局。而通过对新 block 上的策略进行微调,布局的结果还有进一步提升的空间。从头开始训练的策略所需的收敛时间要长得多,甚至在 24 小时后其芯片布局质量仍然不如微调策略 12 小时后的结果。
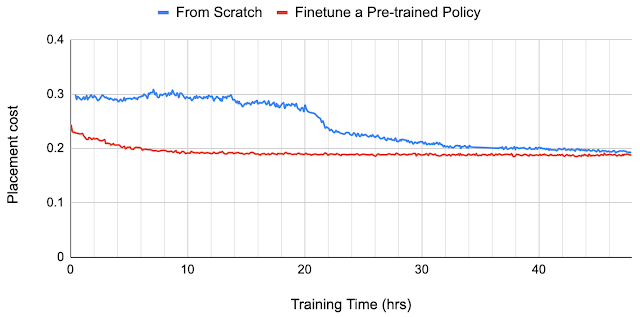
两种策略在 Ariane 块上的收敛图形。其中一个是从头开始训练,另一个则基于预训练的策略进行微调
随着我们在更大型的数据集上进行训练,我们的方法可实现更出色的性能。据观察,随着训练的数据集从两个块增加到五个再上升到 20 个,使用零次方法的策略和微调策略在相同的训练时钟时间下均可生成更好的芯片布局。
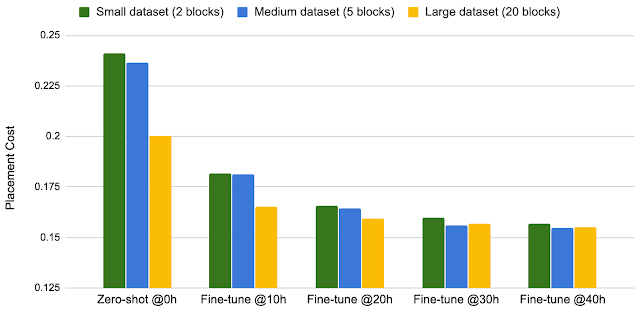
训练数据规模与微调后的性能
我们的方法具备从经验中学习并随时间推移而改进的能力,为芯片设计人员解锁全新的可能性。随着接触到的芯片数量和种类逐渐多,智能体现可更快更好地为新芯片 block 生成优化布局。快速、高质量和自动化的芯片布局方法能够大幅加快芯片设计速度,并与芯片设计过程的早期阶段可实现协同优化。尽管我们主要评估加速器芯片,但我们提出的方法可广泛应用于任何芯片布局问题。在针对机器学习作出如此多的硬件准备之后,我们相信,让机器学习回馈硬件开发的时代已经来临。
致谢
此项目由 Google Research、Google Hardware 和 Google Architecture 团队合作完成。我们在此感谢以下联合作者:Mustafa Yazgan、Joe Jiang、Ebrahim Songhori、Shen Wang、Young-Joon Lee、Eric Johnson、Omkar Pathak、Sungmin Bae、Azade Nazi、Jiwoo Pak、Andy Tong、Kavya Srinivasa、William Hang、Emre Tuncer、Anand Babu、Quoc Le、James Laudon、Roger Carpenter、Richard Ho 和 Jeff Dean,感谢他们对此项研究做出的支持与贡献。
![]()
原文: Chip Design with Deep Reinforcement Learning
中文:TensorFlow 公众号