PhysicalElective2
根据 ‘“tf.matmul (input, kernel) + bias” ,y_pred = a * X + b 写成 y_pred = X * a + b 是不是更好,这样计算下来维度也是正确的
1 reply
根据 ‘“tf.matmul (input, kernel) + bias” ,y_pred = a * X + b 写成 y_pred = X * a + b 是不是更好,这样计算下来维度也是正确的
1 reply


建议可以把 debug 的过程发个帖分享一下看看是否可以帮到更多人~
谢谢,刚刚解决了

训练会受到一些随机因素的影响,CNN 的话 0.99 左右的准确率都是正常的,严谨一点的话可以多运行几次取均值。

w 矩阵是表示卷积核中的权值,一般是通过模型训练得到的。

使用 cats_vs_dogs 数据集,按照下面的模型结构训练 CNN,10 个 epochs 的训练时间将近 3 个小时,请问这个正常吗?
model = tf.keras.Sequential ([
tf.keras.layers.Conv2D (32, 3, activation='relu', input_shape=(256, 256, 3)),
tf.keras.layers.MaxPooling2D (),
tf.keras.layers.Conv2D (32, 5, activation='relu'),
tf.keras.layers.MaxPooling2D (),
tf.keras.layers.Flatten (),
tf.keras.layers.Dense (64, activation='relu'),
tf.keras.layers.Dense (2, activation='softmax')
])如果希望较快速地训练模型的话,可以考虑各种云平台,如 Google 免费的 Colab 或国内的云服务,参考 https://tf.wiki/zh/appendix/cloud.html
模型容量变大的话,我估计主要是因为最后一层的全连接层变大了。去掉了一层卷积层之后,后面的层的参数个数都会变化。
1 reply
“模型的容量”(拟合各种函数的能力)这个说法其实比较模糊,一般认为是和模型的参数数量高度相关。如果想要模型的参数更少的话,可以减少卷积核和神经元个数,以及想办法降低最后一层全连接层的参数数量。关于参数个数的计算方式可参考 https://zhuanlan.zhihu.com/p/77471991
不过如果你实际想要的是让模型训练的速度更快的话,其实最直白的方法是使用 GPU。cats_vs_dogs 数据集相对比较大,而卷积神经网络用 CPU 来训练其实效率非常低下(在大数据集上尤为明显)。这个模型在一个普通性能的 GPU 上(比如 GTX1060)应该几分钟就能训练好。
1 reply
使用 cats_vs_dogs 数据集在第一轮 epoch 训练时,日志信息显示的训练进度是 “44/Unknown”,第二轮可以正常显示训练的数量 “34/776”,请问为什么这里第一轮是 Unknown 呢?训练数据我已下载到本地,加载方式:
train_cat_filenames = tf.constant ([train_cats_dir + filename for filename in os.listdir (train_cats_dir)])
train_dog_filenames = tf.constant ([train_dogs_dir + filename for filename in os.listdir (train_dogs_dir)])
train_dataset = tf.data.Dataset.from_tensor_slices ((train_filenames, train_labels))
train_dataset = train_dataset.map (
map_func=_decode_and_resize,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_dataset = train_dataset.shuffle (buffer_size=23000)
train_dataset = train_dataset.batch (batch_size)
train_dataset = train_dataset.prefetch (tf.data.experimental.AUTOTUNE)
在 mnist 数据集的使用过程中,第一轮的 epoch 日志信息是可以正常显示进度的 “3520/60000”,mnist 的加载方式是通过:
mnist = tf.keras.datasets.mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data ()
请问导致这种差别的原因是什么呢?会对训练得到的模型产生影响,破坏模型的可用性吗?
在训练的过程中还弹出了 “Corrupt JPEG data: 2226 extraneous bytes before marker 0xd9” 这样的 warning, 经过调查发现可能是部分图片本身是 PNG 格式,但是却把后缀名强制改为 jpeg 导致的,这些报出 warning 的图片最终会参与到模型的训练中去吗?model.fit 对这样的内容的处理逻辑是什么样的?

使用 keras subclassing API 定义大模型的时候岂不是会特别臃肿,比如 ResNet150 一类的,因为需要在 init 中定义完全部使用的层并在 call 中指定它们之间的数据流动?

tensorflow2.0 中如何获取模型中某一层的参数,同时把这个参数赋给另外一个相同的神经网络的相同层

@zjrwqdy 请提供具体代码和报错位置。
@zyk516 大部分时候是直接共享相同的层,可以参考本文:https://mp.weixin.qq.com/s/jN4kGT9VCF5ySxtvuqysRg 中关于变量重用的说明。
@asawanggaa 我没有定义过这种极其深层的模型,可以参考一下网上是否有 Keras 或者 PyTorch 的实现。如果它们对这些模型的定义也很 “臃肿 “,那大概用 TensorFlow 2 也差不多。
@slyrx 我估计是把这些图片直接跳过了,当然我没测试过,你可以自己验证一下。
D:\anaconda\python.exe C:/Users/Administrator/PycharmProjects/untitled/3.py
Traceback (most recent call last):
File “C:/Users/Administrator/PycharmProjects/untitled/3.py”, line 37, in
optimizer = tf.keras.optimizers.Adam (learning_rate=learning_rate)
File “D:\anaconda\lib\site-packages\tensorflow\python\keras\optimizers.py”, line 471, in init
super (Adam, self).init(**kwargs)
File “D:\anaconda\lib\site-packages\tensorflow\python\keras\optimizers.py”, line 68, in init
'passed to optimizer: ’ + str (k))
TypeError: Unexpected keyword argument passed to optimizer: learning_rate
Process finished with exit code 1
报错是这个样子的
代码是复制的你 MLP 的代码
谢谢 之前好像是环境搞错了 不好意思啦 但是现在又遇到问题了 麻烦您再帮我看看。还是 MLP 的程序。
D:\anaconda\envs\tf2\python.exe C:/Users/Administrator/PycharmProjects/untitled/3.py
Traceback (most recent call last):
File “C:/Users/Administrator/PycharmProjects/untitled/3.py”, line 1, in
import tensorflow as tf
File “D:\anaconda\envs\tf2\lib\site-packages\tensorflow_init_.py”, line 101, in
from tensorflow_core import *
File “D:\anaconda\envs\tf2\lib\site-packages\tensorflow_core_init_.py”, line 40, in
from tensorflow.python.tools import module_util as _module_util
ModuleNotFoundError: No module named ‘tensorflow.python.tools’; ‘tensorflow.python’ is not a package
Process finished with exit code 1
1 reply
你这个环境配置依然有问题,连 import TensorFlow as tf 都无法正常运行。请先参考一下环境配置的章节内容,检查自己的 tensorflow 是否正确安装。
我看了大部分 keras 模型的定义代码,基本上使用 subclassing API 的都很臃肿。
有一个使用工厂模式 +keras API 的比较简洁,不清楚这两种 API 定义的模型之间是否会有区别,尤其是要和其他技巧配合的时候(比如梯度累积、自定义 loss 和 metric)
def _conv_bn_relu (**conv_params):
filters = conv_params ["filters"]
kernel_size = conv_params ["kernel_size"]
strides = conv_params.setdefault ("strides", (1, 1))
kernel_initializer = conv_params.setdefault ("kernel_initializer", "he_normal")
padding = conv_params.setdefault ("padding", "same")
kernel_regularizer = conv_params.setdefault ("kernel_regularizer", l2 (1.e-4))
def f (input):
conv = Conv2D (filters=filters, kernel_size=kernel_size,
strides=strides, padding=padding,
kernel_initializer=kernel_initializer,
kernel_regularizer=kernel_regularizer)(input)
return _bn_relu (conv)
return f
类似这样的,一层一层套函数,我实验下来貌似没有太大的区别
1 reply
可能要看使用场景,以及 “简洁 / 臃肿” 的定义也比较主观。我认为需要高灵活性的模型比较适合 subclassing api。

dataset = tfds.load (“tf_flowers”, split=tfds.Split.TRAIN, as_supervised=True) 这个数据集无法直接在代码里面下载,问一下是否可以有其他方法下载,如果可以,把下载后的文件放到那个指定的目录啊?
2 replies

请问,如果只运行卷积那部分的代码,就会报错
Failed to get convolution algorithm. This is probably because cuDNN failed to initialize
但是如果先运行 MLP 那部分的代码,再运行卷积部分的,就可以运行,请问这是为什么呢
建议按照 https://tf.wiki/zh_hans/appendix/tfds.html 中的说明设置代理(对了目前貌似是直接设HTTPS_PROXY了,参考 https://github.com/tensorflow/datasets/blob/dd51a2d510bdcbf4498e9dcd2ee1ef33d44a13f3/tensorflow_datasets/core/download/downloader.py#L147 )。我目前没听说过有国内镜像,如果谁发现了也请告诉我。
@ifwant 经过调试发现是预训练模型本身的问题,可参考 https://zhuanlan.zhihu.com/p/64310188 。解决方案是为预训练模型的部分层手动开启训练模式,即加入
tf.keras.backend.set_learning_phase (True)
或者在调用模型的时候加入 training=True 参数,即
labels_pred = model (images, training=True)
我在写这段示例代码的时候没遇到这样的问题,可能是年代久远了。
@LiuPineapple 可能是环境配置的问题,请换个电脑或者在云端运行试试看。


不一样的。前面是矩阵相乘,后面你写的是矩阵中对应位置的元素相乘。
“灰度图像” 与 “黑白图像” 还是有区别的,前者的取值一般在 0-255 之间(即 8 位灰度图像。纯白为 255,纯黑为 0)。

老师,我在官网上下载了 flower_photos.tgz 数据集文件,请问一下该把这个数据集放在哪个文件夹下,然后使用 dataset = tfds.load (“tf_flowers”, split=tfds.Split.TRAIN, as_supervised=True) 就可以加载数据呀?
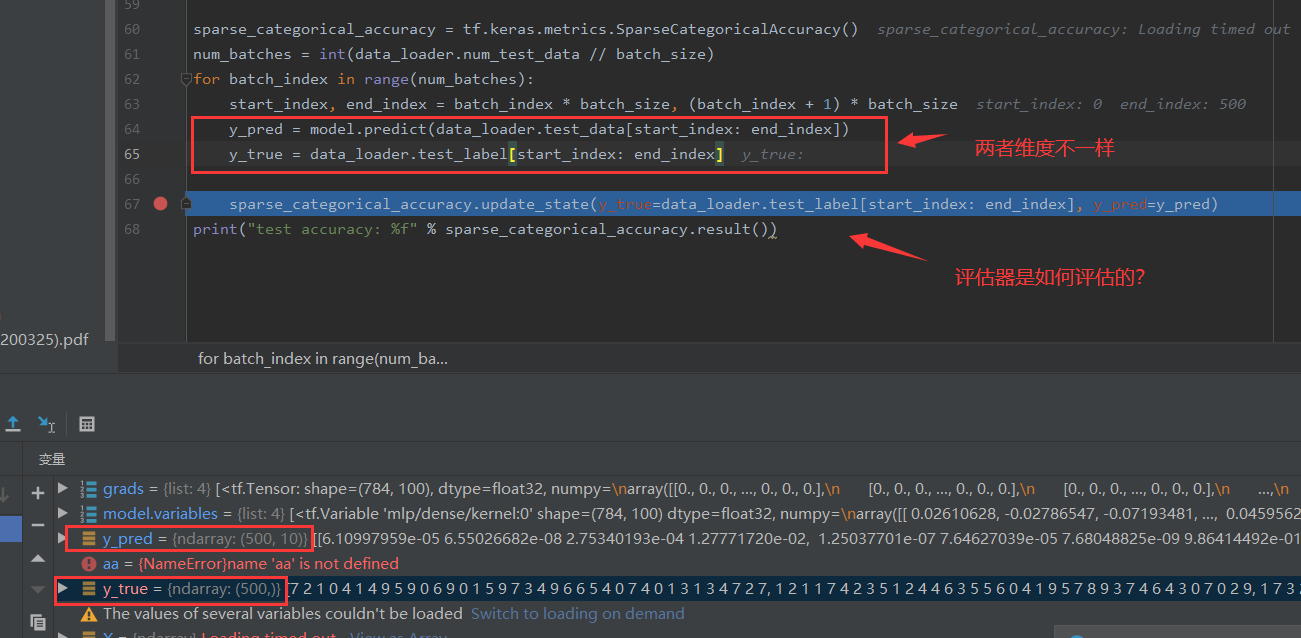
楼主您好,在 MNIST 数据集中,您在建好模型进行模型评估的时候有这么两句:
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index: end_index])
这里 batch_size 是 50,也就是说您每次在 predict 的时候,用了 50 个样本,那么这 50 个样本它们是一个样本计算一个偏差,最后把这 50 个偏差给叠加起来,还是一次性的将 50 个样本作为模型的一个输入,来得到一个偏差?
这个地方不是很懂,因为我在机器学习中,每次 predict 的时候都是单样本作为输入
@Wiiki70450 TensorFlow Datasets 的 tf_flowers 数据集是从 GCS(Google Cloud Storage)上下载的预处理后的数据集。 flower_photos.tgz 仅是预处理前的原始数据集文件,并无法直接使用 tfds.load 加载(可以使用 tf.data 自己处理,仿照教程中给出的 cats_vs_dogs 示例)。如果谁发现了好的手动下载数据集并载入的方法,欢迎告诉我。目前来看,在国内使用 TensorFlow Datasets 最省事的方法还是设置代理。TFDS 默认的数据文件夹为 用户目录 /tensorflow_datasets 。例如在 windows 下是 C:\Users\用户名\tensorflow_datasets 。
@shuhaojie 一次性将 50 个样本作为模型的输入,得到 50 个预测值,分别对应于 50 个样本。
ok,谢谢。昨天你回复我之前,我尝试过将每次的输入样本数改为 1 个,得到的准确率和 50 个输入样本基本一样。后来输入样本数改为 25 个,结果得到的准确率是 0.96。
检查一下你的代码是否与 tensorflow-handbook/rnn.py at master · snowkylin/tensorflow-handbook · GitHub 一致,尤其是 RNN 模型类的 predict 方法是否存在。
2 replies
好的,十分感谢!
@snowkylin 请问设置 HTTPS_PROXY 的这个代理文件在哪里呢?另外,如果把文件下载到本地,“http:// 代理服务器 IP:端口” 这部分怎么填呢?
1 reply
这就属于 “不适宜公开讨论” 的范畴了,建议请教身边的经常上外网的小伙伴。

这里的train_data不是一般的 Python 数组(list),而是 NumPy 数组。NumPy 数组支持各种高级 slicing 操作,请参考 https://numpy.org/doc/1.18/reference/arrays.indexing.html#integer-array-indexing
噢,明白,我用 np 试一下。谢谢大神!

你好,MLP 模型训练中每个 batch 都调用 getbatch 方法,产生 batch_size 个的随机数据,这样每次不是会有重复的吗??
请参考 11.5. 小批量随机梯度下降 — 动手学深度学习 2.0.0 documentation 。这里用了重复采样(所以会有你说的 “重复” 现象)只是为了实现的方便,其实也可以使用不重复采样。正如引文中所说:
我们可以通过重复采样(sampling with replacement)或者不重复采样(sampling without replacement)得到一个小批量中的各个样本。前者允许同一个小批量中出现重复的样本,后者则不允许如此,且更常见。

class CNN (tf.keras.Model):
def __init__(self):
super ().__init__()
self.conv1 = tf.keras.layers.Conv2D (
filters=32,
kernel_size=[5,5],
padding='same',
activation=tf.nn.relu
)
self.pool1 = tf.keras.layers.MaxPool2D (pool_size=[2,2],strides=2)
self.conv2 = tf.keras.layers.Conv2D (
filters=64,
kernel_size=[5,5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D (pool_size=[2,2],strides=2)
self.flatten = tf.keras.layers.Reshape (target_shape=(7*7*64,))
self.dense1 = tf.keras.layers.Dense (units=1024,activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense (units=10)
def call (self,inputs):
x = self.conv1 (inputs)
x = self.pool1 (x)
x = self.conv2 (x)
x = self.pool2 (x)
x = self.flatten (x)
x = self.dense1 (x)
x = self.dense2 (x)
output = tf.nn.softmax (x)
return output
class MNISTLoader ():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data,self.train_label),(self.test_data,self.test_label) = mnist.load_data ()
self.train_data = np.expand_dims (self.train_data.astype (np.float32) / 255.0,axis=-1)
self.test_data = np.expand_dims (self.test_data.astype (np.float32) / 255.0,axis=-1)
self.train_label = self.train_label.astype (np.int32)
self.test_label = self.test_label.astype (np.int32)
self.num_train_data,self.num_test_data = self.train_data.shape [0],self.test_data.shape [0]
def get_batch (self,batch_size):
index = np.random.randint (0,np.shape (self.train_data.shape)[0],batch_size)
return self.train_data [index,:],self.train_label [index]
num_epochs = 5
batch_size = 50
learning_rate = 0.001
model = CNN ()
data_loader = MNISTLoader ()
optimizer = tf.keras.optimizers.Adam (learning_rate=learning_rate)
num_batches = int (data_loader.num_train_data//batch_size*num_epochs)
for batch_index in range (num_batches):
X,y = data_loader.get_batch (batch_size)
with tf.GradientTape () as tape:
y_pred = model (X)
loss = tf.keras.losses.sparse_categorical_crossentropy (y_true=y,y_pred=y_pred)
loss = tf.reduce_mean (loss)
print ("batch %d: loss %f" % (batch_index,loss.numpy ()))
grads = tape.gradient (loss, model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads, model.variables))
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy ()
num_batches = int (data_loader.num_test_data//batch_size)
for batch_index in range (num_batches):
start_index,end_index = batch_index * batch_size,(batch_index+1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index:end_index])
sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index:end_index],y_pred=y_pred)
# sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred)
print ("test accuracy: %f" % sparse_categorical_accuracy.result ())
非常感谢,问题解决了
请问在用 tfds.load 加载数据集时显示 ValueError: Parsing builder name string tf.flowers failed.
The builder name string must be of the following format:
dataset_name [/config_name][:version][/kwargs],然后看你后面说是设置 HTTPS_PROXY 环境变量,请问如何得到代理服务器 IP 和端口呢?
你把tf_flowers打成了tf.flowers,这是报错的原因。
代理服务器 IP 和端口属于不适合公开讨论的范畴。建议咨询身边经常关注国外信息的小伙伴,或者有条件的话使用 Colab。

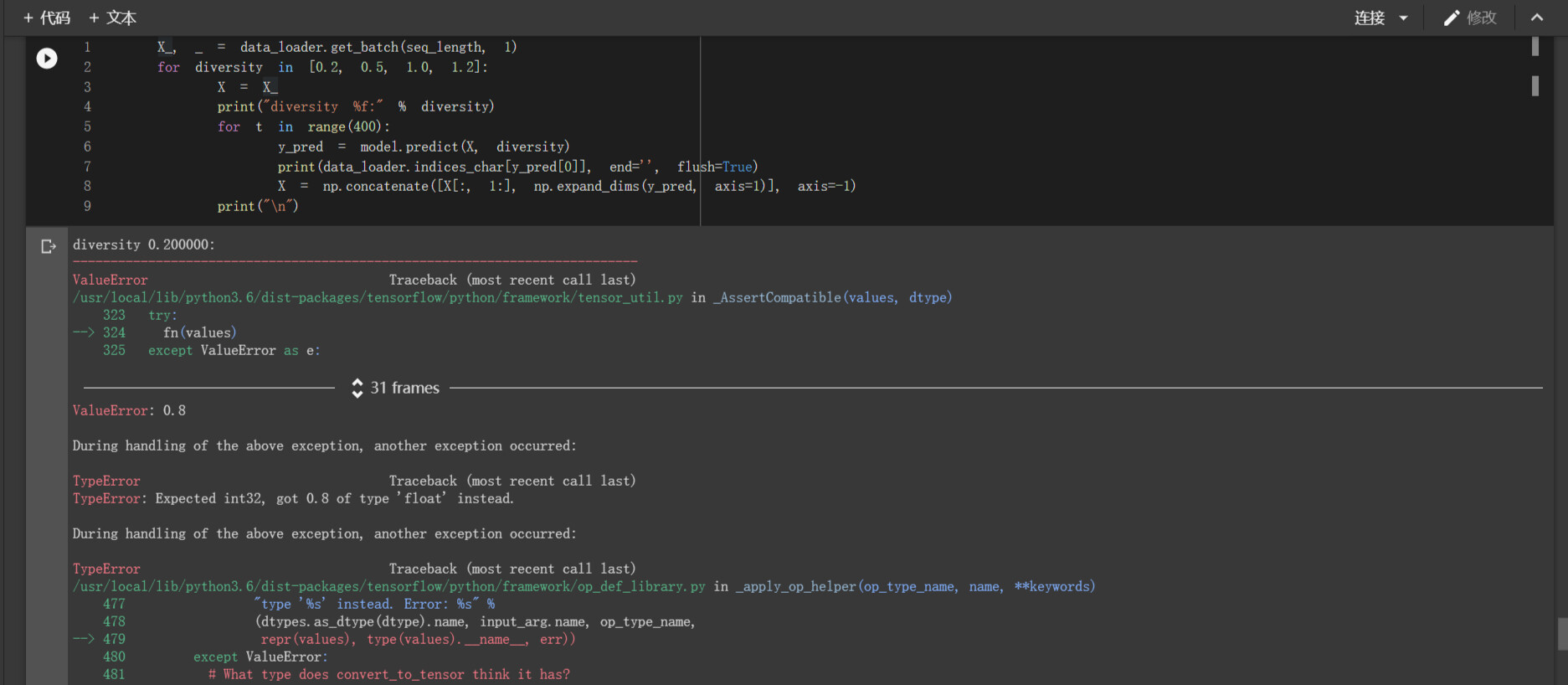
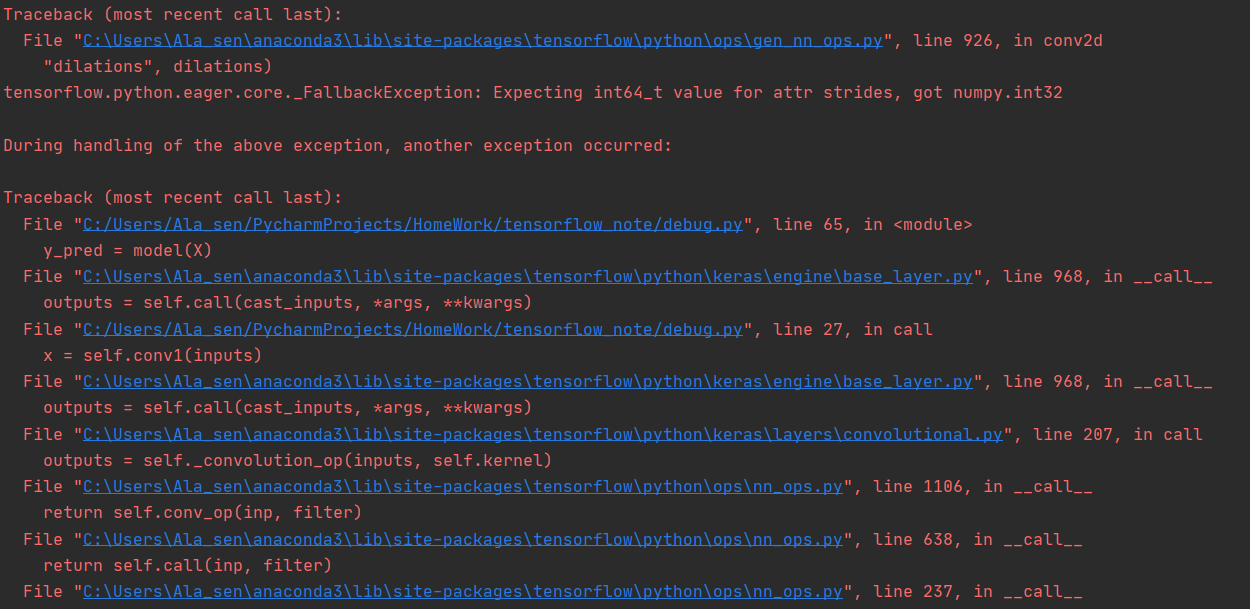
“这个修正后的代码” 指的是哪个代码,请说明或者把这段代码贴出来。看起来是 “一个需要 int64 的地方用了 int32” 的类型问题。
你好,是楼上的 CNN 代码,
import tensorflow as tf
import numpy as np
class CNN (tf.keras.Model):
def __init__(self):
super ().__init__()
self.conv1 = tf.keras.layers.Conv2D (
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding 策略
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPooling2D (pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D (
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPooling2D (pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape (target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense (units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense (units=10)
def call (self, inputs):
x = self.conv1 (inputs) # [batch_size, 28, 28, 32]
x = self.pool1 (x) # [batch_size, 14, 14, 32]
x = self.conv2 (x) # [batch_size, 14, 14, 64]
x = self.pool2 (x) # [batch_size, 7, 7, 64]
x = self.flatten (x) # [batch_size, 7 * 7 * 64]
x = self.dense1 (x) # [batch_size, 1024]
x = self.dense2 (x) # [batch_size, 10]
output = tf.nn.softmax (x)
return output
class MNISTLoader:
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data ()
self.train_data = np.expand_dims (self.train_data.astype (np.float32) / 255, axis=-1)
self.test_data = np.expand_dims (self.test_data.astype (np.float32) / 255, axis=-1)
self.train_label = self.train_label.astype (np.int32)
self.test_label = self.test_label.astype (np.int32)
self.num_train_data, self.num_test_data = self.train_data.shape [0], self.test_data.shape [0]
print (self.num_train_data, self.num_test_data)
def get_batch (self, batch_size):
index = np.random.randint (0, self.num_train_data, batch_size)
return self.train_data [index, :], self.train_label [index]
if __name__ == '__main__':
num_epochs = 5 # 1 个 epoch 表示过了 1 遍训练集中的所有样本
batch_size = 50 # 一次迭代使用的样本量
learning_rate = 0.001
model = CNN ()
data_loader = MNISTLoader ()
optimizer = tf.keras.optimizers.Adam (learning_rate=learning_rate)
num_batches = int (data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range (num_batches):
X, y = data_loader.get_batch (batch_size)
with tf.GradientTape () as tape:
y_pred = model (X)
# 交叉熵作为损失函数
loss = tf.keras.losses.sparse_categorical_crossentropy (y_true=y, y_pred=y_pred)
loss = tf.reduce_sum (loss)
print ('batch %d: loss %f' % (batch_index, loss.numpy ()))
grads = tape.gradient (loss, model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads, model.variables))
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy ()
num_batches = int (data_loader.num_test_data // batch_size)
for batch_index in range (num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index: end_index])
sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred)
print ('test accuracy: %f' % sparse_categorical_accuracy.result ())
下面是完整报错信息,麻烦看一下

我这边在 Colab 里直接运行了一遍代码,并未发现问题。请检查你的 TensorFlow 版本是否为最新的 2.2。如果之前安装过旧版 TensorFlow,建议重新按照 https://tf.wiki/zh_hans/basic/installation.html 配置一遍环境。
1 reply
模型的参数(training variable)和 RNN 的初始状态(initial state)是两个不同的东西,模型训练的是前者而不是后者。请参考一下 TensorFlow 模型建立与训练 — 简单粗暴 TensorFlow 2 0.4 beta 文档 “循环神经网络的工作过程” 和 http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/ 以更深入地了解 RNN 的 “状态” 这一概念。
如果运行 MLP 可以但后面其他的不行,可能说明你的电脑内存或者显卡显存不够。你可以尝试一下调小 batch_size,同时可能也需要参考一下 python 3.x - Tensorflow could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED - Stack Overflow
1 reply
你好,我的 cpu 为 9 代 i716g,gpu 为 1660ti6g,
我加了如下两句代码后可以了,请问一下这是什么问题
gpu_options = tf.compat.v1.GPUOptions (per_process_gpu_memory_fraction=0.333)
sess = tf.compat.v1.Session (config=tf.compat.v1.ConfigProto (gpu_options=gpu_options))

你好,请问可以在使用 tape.gradient 过程中替换其中的求导函数吗?比如替换其中的 relu 函数,以实现 Guided Backprop,或者说以继承 tf.kreas.Modle 的方式定义模型,以 model (X) 的形式使用它,可以便捷的实现 Guided Backprop 吗?
1 reply

GPU 显存不够,改小 Batch Size 试试。
有道理,谢谢~~
本来是想用那个 early stop 的,不过这样一说倒是自己实现一下也可以的。
没想到作者亲自回复,那必须称赞一下,这绝对是看过的写的最好的 TF2 文档,无论是细节还是整体~
我也是 2.2 版本
代码如下
import tensorflow as tf
import numpy as np
# 数据获取及预处理
class MNISTLoader ():
def __init__(self):
mnist=tf.keras.datasets.mnist
(self.train_data,self.train_label),(self.test_data,self.test_label)=mnist.load_data ()
# 预处理,将图像归一化至 0~1 之间的浮点数,并增加最后一维作为颜色通道
self.train_data=np.expand_dims (self.train_data.astype (np.float32)/255.0,axis=-1) #[60000,28,28,1]
self.test_data=np.expand_dims (self.train_data.astype (np.float32)/255.0,axis=-1) #[10000,28,28,1]
self.train_label=self.train_label.astype (np.int32) #[60000]
self.test_label=self.test_label.astype (np.int32) #[10000]
self.num_train_data,self.num_test_data=self.train_data.shape [0],self.test_data.shape [0]
def get_batch (self,batch_size):
# 从数据集中随即取出 batch_size 个元素并返回
index=np.random.randint (0,self.num_train_data,batch_size)
return self.train_data [index,:],self.train_label [index]
# 模型构建
class MLP (tf.keras.Model):
def __init__(self):
super ().__init__()
self.flatten=tf.keras.layers.Flatten ()
self.dense1=tf.keras.layers.Dense (units=100,activation=tf.nn.relu)
self.dense2=tf.keras.layers.Dense (units=10)
def call (self,inputs): #[batch_size,28,28,1]
x=self.flatten (inputs) #[batch_size,784]
x=self.dense1 (x) #[batch_size,100]
x=self.dense2 (x) #[batch_size,10]
output=tf.nn.softmax (x)
return output
# 模型训练
# 定义超参数
num_epochs=5
batch_size=50
learning_rate=0.001
# 实例化模型和数据读取类,实例化优化器
model=MLP ()
data_loader=MNISTLoader ()
optimizer=tf.keras.optimizers.Adam (learning_rate=learning_rate)
# 获取数据并训练
num_batches=int (data_loader.num_train_data//batch_size*num_epochs)
for batch_index in range (num_batches):
X,y=data_loader.get_batch (batch_size)
with tf.GradientTape () as tape:
y_pred=model (X)
loss=tf.keras.losses.sparse_categorical_crossentropy (y_true=y,y_pred=y_pred)
loss=tf.reduce_mean (loss)
print ("batch %d: loss %f"%(batch_index,loss.numpy ()))
grads=tape.gradient (loss,model.variables)
optimizer.apply_gradients (grads_and_vars=zip (grads,model.variables))
# 模型评估
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy ()
num_batches = int (data_loader.num_test_data // batch_size)
for batch_index in range (num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict (data_loader.test_data [start_index: end_index])
sparse_categorical_accuracy.update_state (y_true=data_loader.test_label [start_index: end_index], y_pred=y_pred)
print ("test accuracy: %f"%sparse_categorical_accuracy.result ())
报错如下
感谢博主,问题解决了!修改后的代码在 jupyter notebook 上可以运行了,但是 vscode 依然报一样的错,但也不影响正常运行,我这就去安装 pycharm
再次感谢楼主,vscode 确实是 pylint 出了问题,已找到解决办法!

多谢楼主的指导。我碰到了一个保存模型的问题。用文章里的 tf.saved_model.save 存储模型之后,再用 tf.saved_model.load 提取模型再给新的数据 predict 的时候,报错
Expected these arguments to match one of the following 4 option (s):
Option 1:
Positional arguments (3 total):
* TensorSpec (shape=(None, 72, 72, 5), dtype=tf.float32, name=‘input_1’)
* False
* None
Keyword arguments: {}
我去查了也有人出过这种问题,然后安装了 tb-nightly2.1 这个安装包就解决了。但是我这里安装完 tb-nightly2.4 (只能找到最新的)之后,这个问题还是没有解决。请问楼主有什么建议么?谢谢
1 reply
请提供完整可复现的最小可运行程序代码
问题已经解决了。多谢您的回复。我发现我给的 training data 是 float64 的,但是 layer 的属性是 float32。虽然可以正常去做训练,但是要是用 float64 的数据做 predict 就会报我提到的错误。
不过我还有一个问题,我们在做多分类器训练的时候,丢进去的训练集都是有正确标签的图片,可是并没有空白或其他的图片。例如做猫狗兔训练集的时候,并没有丢给模型猴子的图片。当我对猴子图片或者大海,大山图片做 predict 的时候,这个猫狗兔训练集给出那个 predict 都不对啊。这种情况怎么办?
谢谢

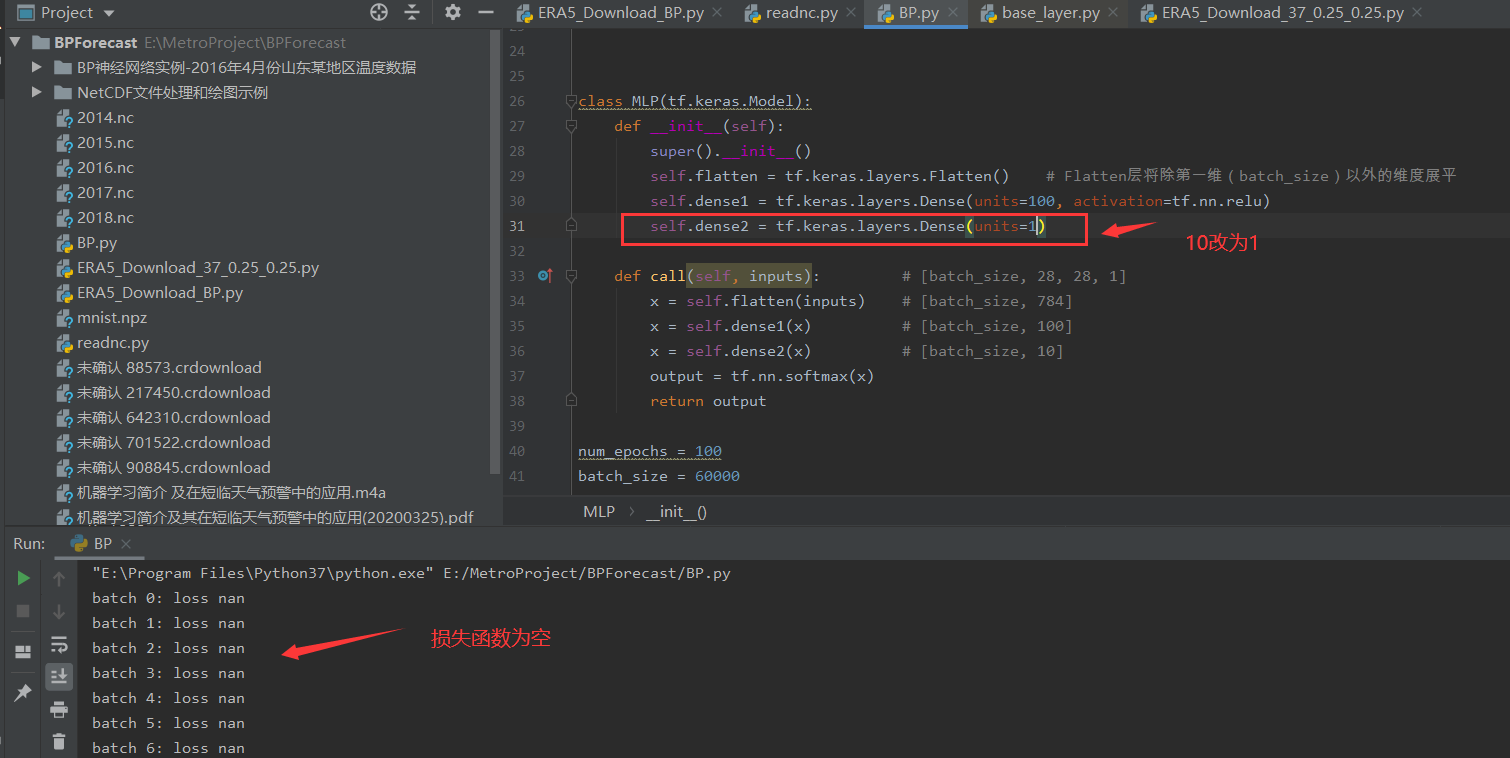
你好,这里的评估器将 y_pred 取 argmax,然后和 y_true 的标签比较,可参考 https://tf.wiki/zh_hans/basic/models.html#id27 里的重实现。这是一个手写数字识别的十分类问题,所以输出层的维度必须为 10,以输出模型预测的 “输入数字分别属于 0~9 的概率”,把输出层改为 1 会导致整个模型失去意义。
1 reply
哦哦,原来是这样,他的索引值等于他的标签值这就说明预测对了,这里我还有几个问题想问一下:
1.不管实际意义,理论上输出 1 个维度也是可以的,但这里报 nan 的信息,是不是在定义 NLP 类时 output = tf.nn.softmax (x) 这里的问题?
2.初始化阈值和权值只能在 tf.keras.layers.Dense 里使用 kernel/bias_initializer 对该层生效,有没有对整个 model 里的所有层生效的方法?
3.假如我构建含很多个隐藏层的方法,不可能在定义 NLP 类时一个一个去定义层,想过用循环写,但是层的变量名是动态的,这好像不太好实现,请问还有更便捷的方法吗?

在运行模型评估 tf.keras.metrics 报错 ValueError: Structure is ascalarbutlen (flat_sequence)==0>1。
请问有人也遇到这种情况吗?该怎么解决?


不好意思之前改了一下用来调试忘了改回去,已修正

class CNN 里面 [28 , 28] 通过感受野 [5, 5] 和 pool1 里面的strides = 2, 那么卷积之后的输出应该是个 [12, 12] 的吧?而不是 call 里面注释后面的 # [batch_size, 14, 14, 32]
@snowkylin
谢谢, 我试试